Thank you for visiting the Causal Analysis in Theory and Practice. We welcome participants from all backgrounds and views to post questions, opinions, or results for other visitors to chew on and respond to. For more information about the blog’s content and logistics, see our About page.
Filed under: Uncategorized — Scott Mueller @ 2:31 am
Scott Mueller and Judea Pearl
Introduction
This note supplements the analysis of [Mueller and Pearl 2023] by introducing an important restriction on the data obtained from Randomized Control Trials (RCT). In Mueller and Pearl, it is assumed that RCTs provide estimates of two probabilities, \(P(y_t)\) and \(P(y_c)\), standing for the probability of the outcome \(Y\) under treatment and control, respectively. In medical practices, however, these two quantities are rarely reported separately; only their difference \(\text{ATE} = P(y_t)-P(y_c)\) is measured, estimated, and reported. The reason is that the individual effects, \(P(y_t)\) and \(P(y_c)\), are suspect of contamination by selection bias and placebo effects. These two imperfections are presumed to cancel out by a method called “Concurrent Control” [Senn 2010] in which subjects in both treatment and control arms are measured simultaneously and only the average difference, ATE, is counted1.
This note establishes bounds on \(P(\text{benefit})\) and \(P(\text{harm})\) under the restriction that RCTs provide only an assessment of ATE, not of the individual causal effects \(P(y_t)\) and \(P(y_c)\). We will show that the new restriction, though leading to wider bounds, still permits the extraction of meaningful information on individual harm and benefit and, when combined with observational data, can be extremely valuable in personalized decision making.
Our results can be summarized in the following two inequalities. The first inequality bounds PNS (same as \(P(\text{benefit})\)) without observational data, and the second bounds PNS using both ATE and observational data in the form of \(P(X, Y)\).
The upper bound in (2), is always lower than (or equal to) the one in (1), because both \(P(x,y) + P(x’,y’) \leqslant 1\) and \(P(x, y’) + P(x’, y) \leqslant 1\).
In Appendix we will present the derivations of Eqs. (1) and (2), whereas in the following section, we discuss some of their ramifications.
Footnote
1
See footnote 11 in [Mueller and Pearl 2023] and [Pearl 2013] for ways in which selection bias can be eliminated when linearity is assumed (after scaling).
How observational data inform PNS (or P(benefit))
The bounds on PNS produced by Eqs. (1) and (2) can be visualized interactively2. To show the contrast between Eq. (1) and Eq. (2), Fig. 1 displays the allowable values of PNS for various levels of ATE, assuming no observational information is available (i.e., Eq. (1)). We see, for example, that for \(\text{ATE} = 0\) (left vertical dashed line), the bound is vacuous (\(0 \leqslant \text{PNS} \leqslant 1\)), while for \(\text{ATE}=0.5\) (right vertical dashed line), we have \(\frac12 \leqslant \text{PNS} \leqslant 1\) — a somewhat more informative bound, but still rather trivial.
Figure 1: The green area represents possible PNS values for the given ATE, while the white areas represent values not achievable by PNS.
Figure 2 displays the allowable values of PNS when observational data are available. We see that for \(\text{ATE} = 0\) (left vertical dashed line), we now have \(0 \leqslant \text{PNS} \leqslant \frac12\), whereas for \(\text{ATE} = 0.5\) (right vertical dashed line), we now have a point estimate \(\text{PNS} = \frac12\), assuring us that exactly 50\% of all subjects will benefit from the treatment (and none will be harmed by it).
Figure 2: The green area represents possible PNS values for the given ATE, while the gray areas represent values of ATE that are incompatible with the assumed observational information: P(y|x) = P(y|x’) = P(x) = 0.5.
When observational data become less symmetric, say \(P(x)=0.5\), \(P(y|x)=0.9\), and \(P(y|x’)=0.1\), the regions of possible and impossible PNS values shift significantly. Moving the sliders for \(P(x)\), \(P(y|x)\), and \(P(y|x’)\) to the above values produces the graph shown in Figure 3. This time, when \(\text{ATE} = 0\) (left vertical dashed line), the bounds on PNS narrow down to \(0 \leqslant \text{PNS} \leqslant 0.1\), telling us that subjects have a maximum 10\% chance of benefiting from the treatment. When \(\text{ATE}=0.5\) (right vertical dashed line), we have \(\frac12 \leqslant \text{PNS} \leqslant 0.6\), still a narrow width of \(0.1\), with an assurance of at least 50\% chance of benefiting from the treatment.
It should be clear now that consequential information on individual benefit can be obtained even when separate causal effects, \(P(y_x)\) and \(P(y_{x’})\), are unavailable. The same situation holds for \(P(\text{harm})\) as well.
Figure 3: The green area represents possible PNS values for the given ATE and observational probabilities: P(x) = 0.5, P(y|x) = 0.9, P(y|x’) = 0.1.
How Observational Data inform the Probability of Harm P(harm)
The probability of harm is the converse of PNS. We can bound this probability with ATE and with observational data similar to Eqs. (1) and (2). With just the ATE, \(P(\text{harm})\) is bounded as:
The lower bound is positive when ATE is positive, and the upper bound is less than \(1\) when ATE is negative. When we combine observational data, a smaller upper bound is possible:
Again, the upper bound in (4), is always lower than (or equal to) the one in (3), since \(P(x,y) + P(x’,y’) \leqslant 1\) and \(P(x, y’) + P(x’, y) \leqslant 1\). See Appendix for the derivations of Eqs. (3) and (4).
Figures 4a and 4b depict these bounds under the same conditions as Figures 1 and 2, respectively.
Figure 4: P(harm) graphs corresponding to Figures 1 and 2 for PNS.
Figure 5, on the other hand, shows very different sets of bounds for the asymmetric case: \(P(x) = 0.5\), \(P(y|x) = 0.9\), and \(P(y|x’) = 0.1\), used in Figure 3. This time, \(0 \leqslant P(\text{harm}) \leqslant 0.1\) when \(\text{ATE}=0\) or \(\text{ATE}=0.5\). This has the same width of \(0.1\) as in the case of PNS, but with a substantially different shape.
Figure 5: The green area represents possible P(harm) values for the given ATE and observational probabilities: P(x)= 0.5, P(y|x) = 0.9, P(y|x’) = 0.1.
Intuition
The intuition behind the PNS lower bound is that the probability of benefiting cannot be less than the positive part of the difference in causal effects. That difference must be explained by benefiting from treatment.
The intuition behind the PNS upper bound is split into two parts. First, the benefiters must be among the individuals who chose treatment and had a successful outcome, \((x, y)\), or those who avoided treatment and had an unsuccessful outcome, \((x’, y’)\). Therefore, one potential upper bound is \(P(x,y) + P(x’,y’)\). Alternatively, since \(\text{ATE} = \text{PNS} – P(\text{harm})\), we get an upper bound on PNS by adding at least the proportion of individuals harmed to ATE. This is precisely the upper bound \(\text{ATE} + P(x, y’) + P(x’, y)\) because the proportion of individuals choosing treatment and having an unsuccessful outcome, \(P(x, y’)\), and the proportion of individuals avoiding treatment and having a successful outcome, \(P(x’, y)\), comprise all individuals harmed by treatment as well as some additional individuals.
Similar reasoning holds for the lower and upper bounds of \(P(\text{harm})\).
Bounds on ATE
In addition to informing PNS and \(P(\text{harm})\), observational data also impose restrictions on ATE, violations of which imply experimental imperfections. We start with Tian and Pearl’s bounds on causal effects [Tian and Pearl 2000]:
While the range of ATE values has a width of \(1\), the location of this range can still alert the experimenter to possible incompatibilities between the observational and experimental data.
Appendix
The lower and upper bounds in Equation (2) follow directly from the Tian-Pearl bounds on PNS. There are two additional possible lower bounds on PNS: \(P(y_x) – P(y)\) and \(P(y) – P(y_{x’})\). Since \(P(y_x) – P(y) = \text{ATE} + P(y_{x’}) – P(y)\) and \(P(y_{x’}) \geqslant 0\), a potential lower bound of \(\text{ATE} – P(y)\) could be added to the \(\max\) function of the left inequality (2). However, the existing lower bound \(\text{ATE}\) subsumes it because \(P(y) \geqslant 0\). Similarly, since \(P(y) – P(y_{x’}) = \text{ATE} – P(y_x) + P(y)\) and \(P(y_x) \leqslant 1\), a potential lower bound of \(\text{ATE} – P(y’)\) could be added to inequalities (2). Again, the existing lower bound \(\text{ATE}\) subsumes it.
There are two additional possible upper bounds on PNS: \(P(y_x)\) and \(P(y’_{x’})\). Since \(P(y_x) = \text{ATE} + P(y_{x’})\) and \(P(y_{x’}) \leqslant 1\), a potential upper bound of \(\text{ATE} + 1\) could be added to the \(\min\) function of the right inequality (2). However, the existing upper bound \(\text{ATE} + P(x, y’) + P(x’, y)\) subsumes it because \(P(x, y’) + P(x’, y) \leqslant 1\). Similarly, since \(P(y’_{x’}) = \text{ATE} + 1 – P(y_x) = \text{ATE} + P(y’_x)\) and \(P(y’_x) \leqslant 1\), a potential upper bound of \(\text{ATE} + 1\) could be added to inequalities (2). Again, the existing upper bound \(\text{ATE} + P(x, y’) + P(x’, y)\) subsumes it.
It may appear that the upper bound might dip below the lower bound, which would be problematic. In particular, either of the following two cases would cause this situation:
Neither of these inequalities can occur because of the inequalities in (7). Inequality (8) cannot occur because of the right inequality of (7). Similarly, inequality (9) cannot occur because of the left inequality of (7).
References
Mueller, Scott and Judea Pearl (2023). “Personalized Decision Making – A Conceptual Introduction”. In: Journal of Causal Inference. url: http://ftp.cs.ucla.edu/pub/stat_ser/r513.pdf.
Pearl, Judea (May 29, 2013). “Linear Models: A Useful “Microscope” for Causal Analysis”. In: Journal of Causal Inference 1.1, pp. 155–170. issn: 2193-3685, 2193-3677. doi: 10.1515/jci-2013-0003. url: https://www.degruyter.com/document/doi/10.1515/jci-2013-0003/html (visited on 03/16/2023).
Tian, Jin and Judea Pearl (2000). “Probabilities of causation: Bounds and identification”. In: Annals of Mathematics and Artificial Intelligence 28.1-4, pp. 287–313. url: http://ftp.cs.ucla.edu/pub/stat_ser/r271-A.pdf.
2022 has witnessed a major upsurge in the status of CI, primarily in its general recognition as an independent and essential component in every aspect of intelligent decision making. Visible evidence of this recognition were several prestigious prizes awarded explicitly to CI-related research accomplishments. These include (1) the Nobel Prize in economics, awarded to David Card, Joshua Angrist, and Guido Imbens for their works on cause and effect relations in natural experiments https://www.nobelprize.org/prizes/economic-sciences/2021/press-release/ (2) The BBVA Frontiers of Knowledge Award to Judea Pearl for “laying the foundations of modern AI” https://www.eurekalert.org/news-releases/942893 and (3) The Rousseeuw Prize for Statistics to Jamie Robins, Thomas Richardson, Andrea Rotnitzky, Miguel Hernán, and Eric Tchetchgen Tchetchgen, for their “pioneering work on Causal Inference with applications in Medicine and Public Health” https://www.rousseeuwprize.org/news/winners-2022.
w
My acceptance speech at the BBVA award can serve as a gentle summary of the essence of causal inference, its basic challenges and major achievements: https://www.youtube.com/watch?v=uaq389ckd5o.
It is not a secret that I have been critical of the approach Angrist and Imbens are taking in econometrics, for reasons elaborated here https://ucla.in/2FwdsGV, and mainly here https://ucla.in/36EoNzO. I nevertheless think that their selection to receive the Nobel Prize in economics is a positive step for CI, in that it calls public attention to the problems that CI is trying to solve and will eventually inspire curious economists to seek a more broad-minded approach to these problems, so as to leverage the full arsenal of tools that CI has developed.
Coupled with these highlights of recognition, 2022 has seen a substantial increase in CI activities on both the academic and commercial fronts. The number of citations to CI related articles has reached a record high of over 10,200 citations in 2022, https://scholar.google.com/citations?user=bAipNH8AAAAJ&hl=en , showing positive derivatives in all CI categories. Dozens, if not hundreds of seminars, workshops and symposia have been organized in major conferences to disseminate progress in CI research. New results on individualized decision making were prominently featured in these meetings (e.g., https://ucla.in/33HSkNI). Several commercial outfits have come up with platforms for CI in their areas of specialization, ranging from healthcare to finance and marketing. (Company names such as #causallense, and Vianai Systems come to mind:
I am also happy to see CI becoming an issue of contention in AI and Machine Learning (ML), increasingly recognized as an essential capability for human-level AI and, simultaneously, raising the question of whether the data-fitting methodologies of Big Data and Deep Learning could ever acquire these capabilities. Inhttps://ucla.in/3d2c2Fi I’ve answered this question in the negative, though various attempts to dismiss CI as a species of “inductive bias” (e.g., https://www.youtube.com/watch?v=02ABljCu5Zw) or “missing data problem” (e.g., https://www.jstor.org/stable/pdf/26770992.pdf) are occasionally being proposed as conceptualizations that could potentially replace the tools of CI. The Ladder of Causation tells us what extra-data information would be required to operationalize such metaphorical aspirations.
Researchers seeking a gentle introduction to CI are often attracted to multi-disciplinary forums or debates, where basic principles are compiled and where differences and commonalities among various approaches are compared and analyzed by leading researchers. Not many such forums were published in 2022, perhaps because the differences and commonalities are now well understood or, as I tend to believe, CI and its Structural Causal Model (SCM) unifies and embraces all other approaches. I will describe two such forums in which I participated.
(1) In March of 2022, the Association for Computing Machinery (ACM) has published an anthology containing highlights of my works (1980-2020) together with commentaries and critics from two dozens authors, representing several disciplines. The Table of Content can be seen here: https://ucla.in/3hLRWkV. It includes 17 of my most popular papers, annotated for context and scope, followed by 17 contributed articles of colleagues and critics. The ones most relevant to CI in 2022 are in Chapters 21-26.
Among these, I consider the causal resolution of Simpson’s paradox (Chapter 22, https://ucla.in/2Jfl2VS) to be one of the crown achievements of CI. The paradox lays bare the core differences between causal and statistical thinking, and its resolution brings an end to a century of debates and controversies by the best philosophers of our time. It is also related to Lord’s Paradox (see https://ucla.in/2YZjVFL) − a qualitative version of Simpson’s Paradox which became a focus of endless debates with statisticians and trialists throughout 2022 (on Twitter @yudapearl). I often cite Simpson’s paradox as a proof that our brain is governed by causal, not statistical, calculus.
This question − causal or statistical brain − is not a cocktail party conversation but touches on the practical question of choosing an appropriate language for casting the knowledge necessary for commencing any CI exercise. Philip Dawid − a proponent of counterfactual-free statistical languages − has written a critical essay on the topic (https://www.degruyter.com/document/doi/10.1515/jci-2020-0008/html?lang=en) and my counterfactual-based rebuttal, https://ucla.in/3bXCBy3, clarifies the issues involved.
(2) The second forum of inter-disciplinary discussions can be found in a special issue of the Journal Observational Studies, https://muse.jhu.edu/pub/56/article/867085/pdf (edited by Ian Shrier, Russell Steele, Tibor Schuster and Mireille Schnitzer) in a form of interviews with Don Rubin, Jamie Robins, James Heckman and myself.
In my interview, https://ftp.cs.ucla.edu/pub/stat_ser/r523.pdf, I compiled aspects of CI that I normally skip in scholarly articles. These include historical perspectives of the development of CI, its current state of affairs and, most importantly for our purpose, the lingering differences between CI and other frameworks. I believe that this interview provides a fairly concise summary of these differences, which have only intensified in 2022.
Most disappointing to me are the graph-avoiding frameworks of Rubin, Angrist, Imbens and Heckman, which still dominate causal analysis in economics and some circles of statistics and social science. The reasons for my disappointments are summarized in the following paragraph:
Graphs are new mathematical objects, unfamiliar to most researchers in the statistical sciences, and were of course rejected as “non-scientific ad-hockery” by top leaders in the field [Rubin, 2009]. My attempts to introduce causal diagrams to statistics [Pearl, 1995; Pearl, 2000] have taught me that inertial forces play at least as strong a role in science as they do in politics. That is the reason that non-causal mediation analysis is still practiced in certain circles of social science [Hayes, 2017], “ignorability” assumptions still dominate large islands of research [Imbens and Rubin, 2015], and graphs are still tabooed in the econometric literature [Angrist and Pischke, 2014]. While most researchers today acknowledge the merits of graph as a transparent language for articulating scientific information, few appreciate the computational role of graphs as “reasoning engines,” namely, bringing to light the logical ramifications of the information used in their construction. Some economists even go to great pains to suppress this computational miracle [Heckman and Pinto, 2015; Pearl, 2013].
My disagreements with Heckman go back to 2007 when he rejected the do-operator for metaphysical reasons (see https://ucla.in/2NnfGPQ#page=44) and then to 2013, when he celebrated the do-operator after renaming it “fixing” but remained in denial of d-separation (see https://ucla.in/2L8OCyl). In this denial he retreated 3 decades in time while castrating graphs from their inferential power. Heckman’s 2022 interview in Observational Studies continues his on-going crusade to prove that econometrics has nothing to learn from neighboring fields. His fundamental mistake lies in assuming that the rules of do-calculus lie “outside of formal statistics”; they are in fact logically derivable from formal statistics, REGARDLESS of our modeling assumptions but (much like theorems in geometry) once established, save us the labor of going back to the basic axioms.
My differences with Angrist, Imbens and Rubin go even deeper (see https://ucla.in/36EoNzO), for they involve not merely the avoidance of graphs but also the First Law of Causal Inference (https://ucla.in/2QXpkYD) hence issues of transparency and credibility. These differences are further accentuated in Imbens’s Nobel lecture https://onlinelibrary.wiley.com/doi/pdf/10.3982/ECTA21204which treats CI as a computer science creation, irrelevant to “credible” econometric research. In https://ucla.in/2L8OCyl, as well as in my book Causality, I present dozens of simple problems that economists need, but are unable to solve, lacking the tools of CI.
It is amazing to watch leading researchers, in 2022, still resisting the benefits of CI while committing their respective fields to the tyranny of outdatedness.
To summarize, 2022 has seen an unprecedented upsurge in CI popularity, activity and stature. The challenge of harnessing CI tools to solve critical societal problems will continue to inspire creative researchers from all fields, and the aspirations of advancing towards human-level artificial intelligence will be pursued with an accelerated pace in 2023.
I have posted a couple of comments there, expressing my bewilderment, and summarized them in the following statement:
Andrew, Re-reading your post, I pause at every line that mentions “causal inference” and I say to myself: This is not my “causal inference,” and if Andrew is right that this is what statisticians mean by “causal inference,” then there are two non intersecting kinds of “causal inference” in the world, one used by statisticians and one by people in my culture whom, for lack of better words, I call “Causal Inference Folks.”
I cannot go over every line, but here is a glaring one: “causal inference is all about the aggregation of individual effects into average effects, and if you have a direct model for individual effects, then you just fit it directly.”
Not in my culture. I actually go from average effects to individual effects. See https://ucla.in/3aZx2eQ and https://ucla.in/33HSkNI. Moreover, I have never seen “a direct model for individual effects” unless it is an SCM. Is that what you had in mind? If so, how does it differ from a “mechanistic model.” What would I be missing if I use SCM and never mention “mechanistic models”?
Bottom line, your post reinforces my explicit distinction between “statisticians” and “causal inference folks” to the point where I can hardly see an overlap. To make it concrete, let me ask a quantitative question: How many “statisticians” do you know who subscribe to the First Law of Causal Inference https://ucla.in/2QXpkYD, or to the Ladder of Causation https://ucla.in/2URVLZW, or to the backdoor criterion or etc? These are foundational notions that we “causal inference folks” consider to be the DNA of our culture, without which we are back in pre-1990 era.
For us, “Causal” is not like “error term”: it’s what we say when we ARE trying to model the process.
Personalized decision making targets the behavior of a specific individual, while population-based decision making concerns a sub-population resembling that individual. This paper clarifies the distinction between the two and explains why the former leads to more informed decisions. We further show that by combining experimental and observational studies we can obtain valuable information about individual behavior and, consequently, improve decisions over those obtained from experimental studies alone.
Introduction
The purpose of this paper is to provide a conceptual understanding of the distinction between personalized and population-based decision making, and to demonstrate both the advantages of the former and how it could be achieved.
Formally, this distinction is captured in the following two causal effects. Personalized decision making optimizes the Individual Causal Effect (ICE):
where \(Y(x,u)\) stands for the outcome that individual \(u\) would attain had decision \(x \in \{1, 0\}\) been taken. In contrast, population-based decision making optimizes the Conditional Average Causal Effect (CACE):
where \(C(u)\) stands for a vector of characteristics observed on individual \(u\), and the average is taken over all units \(u’\) that share these characteristics.
We will show in this paper that the two objective functions lead to different decision strategies and that, although \(\text{ICE}(u)\) is in general not identifiable, informative bounds can nevertheless be obtained by combining experimental and observational studies. We will further demonstrate how these bounds can improve decisions that would otherwise be taken using \(\text{CACE}(u)\) as an objective function.
The paper is organized as follows. Section 2 will demonstrate, using an extreme example, two rather surprising findings. First, that population data are capable of providing decisive information on individual response and, second, that non-experimental data, usually discarded as bias-prone, can add information (regarding individual response) beyond that provided by a Randomized Controlled Trial (RCT) alone. Section 3 will generalize these findings using a more realistic example, and will further demonstrate how critical decisions can be made using the information obtained and their ramifications to both the targeted individual and to a population-minded policy maker. Section 4 casts the findings of Section 3 in a numerical setting, allowing for a quantitative appreciation of the magnitudes involved. This analysis leads to actionable policies that guarantee risk-free benefits in certain populations.
Preliminary Semi-qualitative Example
Our target of analysis is an individual response to a given treatment, namely, how an individual would react if given treatment and if denied treatment. Since no individual can be subjected to both treatment and its denial, its response function must be inferred from population data, originating from one or several studies. We are asking therefore: to what degree can population data inform us about an individual response?
Before tackling this general question, we wish to address two conceptual hurdles. First, why should population data provide any information whatsoever on the individual response and, second, why should non-experimental data add any information (regarding individual response) to what we can learn with an RCT alone. The next simple example will demonstrate both points.
We conduct an RCT and find no difference between treatment (drug) and control (placebo), say \(10\%\) in both treatment and control groups die, while the rest (\(90\%\)) survive. This makes us conclude that the drug is ineffective, but also leaves us uncertain between (at least) two competing models:
Model-1 — The drug has no effect whatsoever on any individual and
Model-2 — The drug saves \(10\%\) of the population and kills another \(10\%\).
From a policy maker viewpoint the two models may be deemed equivalent, the drug has zero average effect on the target population. But from an individual viewpoint the two models differ substantially in the sets of risks and opportunities they offer. According to Model-1, the drug is useless but safe. According to Model-2, however, the drug may be deemed dangerous by some and a life-saver by others.
To see how such attitudes may emerge, assume, for the sake of argument, that the drug also provides temporary pain relief. Model-1 would be deemed desirable and safe by all, whereas Model-2 will scare away those who do not urgently need the pain relief, while offering a glimpse of hope to those whose suffering has become unbearable, and who would be ready to risk death for the chance (\(10\%\)) of recovery. (Hoping, of course, they are among the lucky beneficiaries.)
This simple example will also allow us to illustrate the second theme of our paper – the crucial role of observational studies. We will now show that supplementing the RCT with an observational study on the same population (conducted, for example, by an independent survey of patients who have the option of taking or avoiding the drug) would allow us to decide between the two models, totally changing our understanding of what risks await an individual taking the drug.
Consider an extreme case where the observational study shows \(100\%\) survival in both drug-choosing and drug-avoiding patients, as if each patient knew in advance where danger lies and managed to avoid it. Such a finding, though extreme and unlikely, immediately rules out Model-1 which claims no treatment effect on any individual. This is because the mere fact that patients succeed \(100\%\) of the time to avoid harm where harm does exist (revealed through the \(10\%\) death in the randomized trial) means that choice makes a difference, contrary to Model-1’s claim that choice makes no difference.
The reader will surely see that the same argument applies when the probability of survival among option-having individuals is not precisely \(100\%\) but simply higher (or lower) than the probability of survival in the RCT. Using the RCT study alone, in contrast, we were unable to rule out Model-1, or even to distinguish Model-1 from Model-2.
We now present another edge case where Model-2, rather than Model-1, is ruled out as impossible. Assume the observational study informs us that all those who chose the drug died and all who avoided the drug survived. It seems that drug-choosers were truly dumb while drug-avoiders knew precisely what’s good for them. This is perfectly feasible, but it also tells us that no one can be cured by the drug, contrary to the assertion made by Model-2, that the drug cures \(10\%\) and kills \(10\%\). To be cured, a person must survive if treated and die if not treated. But none of the drug-choosers were cured, because they all died, and none of the drug avoiders were cured because they all survived. Thus, Model-2 cannot explain these observational results, and must be ruled out.
Now that we have demonstrated conceptually how certain combinations of observational and experimental data can provide information on individual behavior that each study alone cannot, we are ready to go to a more realistic motivating example which, based on theoretical bounds derived in Tian and Pearl, 2000, establishes individual behavior for any combination of observational and experimental data1 and, moreover, demonstrates critical decision making ramifications of the information obtained.
Footnote
1
The example we will work out happened to be identifiable due to particular combinations of data, though, in general, the data may not permit point estimates of individual causal effects.
Motivating Numerical Example
The next example to be considered deals with the effect of a drug on two subpopulations, males and females. Unlike the extreme case considered in Section 2, the drug is found to be somewhat effective for both males and females and, in addition, deaths are found to occur in the observational study as well.
To cast the story in a realistic setting, we imagine the testing of a new drug, aimed to help patients suffering from a deadly disease. An RCT is conducted to evaluate the efficacy of the drug and is found to be \(28\%\) effective in both males and females. In other words \(\text{CACE}(\text{male}) = \text{CACE}(\text{female}) = 0.28\). The drug is approved and, after a year of use, a follow up randomized study is conducted yielding the same results; namely CACE remained 0.28, and men and women remained totally indistinguishable in their responses, as shown in Table 1.
Experimental
\(do(\text{drug})\)
\(do(\text{no drug})\)
\(\text{CACE}\)
Female Survivals
489/1000 (49%)
210/1000 (21%)
28%
Male Survivals
490/1000 (49%)
210/1000 (21%)
28%
Table 1: Female vs male CACE
Female Data
Experimental
Observational
\(do(\text{drug})\)
\(do(\text{no drug})\)
\(\text{drug}\)
\(\text{no drug}\)
Survivals
489 (49%)
210 (21%)
378 (27%)
420 (70%)
Deaths
511 (51%)
790 (79%)
1,022 (73%)
180 (30%)
Total
1,000 (50%)
1,000 (50%)
1,400 (70%)
600 (30%)
Table 2: Female survival and recovery data
Male Data
Experimental
Observational
\(do(\text{drug})\)
\(do(\text{no drug})\)
\(\text{drug}\)
\(\text{no drug}\)
Survivals
490 (49%)
210 (21%)
980 (70%)
420 (70%)
Deaths
510 (51%)
790 (79%)
420 (30%)
180 (30%)
Total
1,000 (50%)
1,000 (50%)
1,400 (70%)
600 (30%)
Table 3: Male survival and recovery data
Let us focus on the second RCT (Table 1), since the first was used for drug approval only, and its findings are the same as the second. The RCT tells us that there was a \(28\%\) improvement, on average, in taking the drug compared to not taking the drug. This was the case among both females and males: \(\text{CACE}(\text{female}) = \text{CACE}(\text{male}) = 0.28\), where \(do(\text{drug})\) and \(do(\text{no-drug})\) are the treatment and control arms in the RCT. It thus appears reasonable to conclude that the drug has a net remedial effect on some patients and that every patient, be it male or female, should be advised to take the drug and benefit from its promise of increasing one’s chances of recovery (by \(28\%\)).
At this point, the drug manufacturer ventured to find out to what degree people actually buy the approved drug, following its recommended usage. A market survey was conducted (observational study) and revealed that only \(70\%\) of men and \(70\%\) of women actually chose to take the drug; problems with side effects and rumors of unexpected deaths may have caused the other \(30\%\) to avoid it. A careful examination of the observational study has further revealed substantial differences in survival rates of men and women who chose to use the drug (shown in Tables 2 and 3). The rate of recovery among drug-choosing men was exactly the same as that among the drug-avoiding men (\(70\%\) for each), but the rate of recovery among drug-choosing women was \(43\%\) lower than among drug-avoiding women (\(0.27\) vs \(0.70\), in Table 2). It appears as though many women who chose the drug were already in an advanced stage of the disease, which may account for their low recovery rate of \(27\%\).
At this point, having data from both experimental and observational studies we can estimate the individual treatment effects for both a typical man and a typical woman. Quantitative analysis shows (see Section 4) that, with the data above, the drug affects men markedly differently from the way it affects women. Whereas a woman has a \(28\%\) chance of benefiting from the drug and no danger at all of being harmed by it, a man has a \(49\%\) chance of benefiting from it and as much as a \(21\%\) chance of dying because of it — a serious cause for concern. Note that based on the experimental data alone (Table 1), no difference at all can be noticed between men and women.
The ramifications of these findings on personal decision making are enormous. First, they tell us that the drug is not as safe as the RCT would have us believe, it may cause death in a sizable fraction of patients. Second, they tell us that a woman is totally clear of such dangers, and should have no hesitation to take the drug, unlike a man, who faces a decision; a \(21\%\) chance of being harmed by the drug is cause for concern. Physicians, likewise, should be aware of the risks involved before recommending the drug to a man. Third, the data tell policy makers what the overall societal benefit would be if the drug is administered to women only; \(28\%\) of the drug-takers would survive who would die otherwise. Finally, knowing the relative sizes of the benefiting vs harmed subpopulations swings open the door for finding the mechanisms responsible for the differences as well as identifying measurable markers that characterize those subpopulations.
For example:
In the same way that our analysis has identified “Sex” to be an important feature, separating those who are harmed from those saved by the drug, so we can leverage other measured features, say family history, a genetic marker, or a side-effect, and check whether they shrink the sizes of the susceptible subpopulations. The results would be a set of features that approximate responses at the individual level. Note again that absent observational data and a calculus for combining them with the RCT data, we would not be able to identify such informative features. A feature like “Sex” would be deemed irrelevant, since men and women were indistinguishable in our RCT studies.
Our ability to identify relevant informative features as described above can be leveraged to amplify the potential benefits of the drug. For example, if we identify a marker that characterizes men who would die only if they take the drug and prevent those patients from taking the drug, the drug would cure \(62\%\) of male patients who would be allowed to use it. This is because we don’t administer the drug to the \(21\%\) who would’ve been killed by the drug. Those patients will now survive, so a total of \(70\%\) of patients will be cured because of this combination of marker identification and drug administration. This unveils an enormous potential of the drug at hand, which was totally concealed by the \(28\%\) effectiveness estimated in the RCT studies.
How the Results Were Obtained
For the purpose of analysis, let us denote \(y_t\) as recovery among the RCT treatment group and \(y_c\) as recovery among the RCT control group. The causal effects for treatment and control groups, \(P(y_t|\text{Gender})\) and \(P(y_c|\text{Gender})\), were the same2, no differences were noted between males and females.
In addition to the above RCT3, we posited an observational study (survey) conducted on the same population. Let us denote \(P(y|t, \text{Gender})\) and \(P(y|c, \text{Gender})\) as recovery among the drug-choosers and recovery among the drug-avoiders, respectively.
With this notation at hand, our problem is to compute the probability of benefit
from the following data sources: \(P(y_t)\), \(P(y_c)\), \(P(y|t)\), \(P(y|c)\), and \(P(t)\). The first two denote the data obtained from the RCT and the last three, data obtained from the survey. Eq. (3) should be interpreted as the probability that an individual would both recover if assigned to the RCT treatment arm and die if assigned to control4.
Connecting the experimental and observational data is an important assumption known as consistency (Pearl, 2009, 2010)5. In other words, we assume that the units selected for an observational or experimental study are drawn from the same population and that their response to treatment is purely biological, unaffected by their respective settings.
In other words, the outcome of a person choosing the drug would be the same had this person been assigned to the treatment group in an RCT study. Similarly, if we observe someone avoiding the drug, their outcome is the same as if they were in the control group of our RCT. Deviation from consistency, normally attributed to uncontrolled “placebo effects”, should be dealt with by explicitly representing such factors in the model.
In words, the probability that a drug-chooser would recover in the treatment arm of the RCT, \(P(y_t|t)\), is the same as the probability of recovery in the observational study, \(P(y|t)\).
Based on this assumption, and leveraging both experimental and observational data, Tian and Pearl (Tian and Pearl, 2000) derived the following tight bounds on the probability of benefit, as defined in (3):
Here \(P(y’_c)\) stands for \(1-P(y_c)\), namely the probability of death in the control group. The same bounds hold for any subpopulation, say males or females, if every term in (5) is conditioned on the appropriate class.
Applying these expressions to the female data from Table 2 gives the following bounds on \(P(\text{benefit}|\text{female})\):
We aren’t always so fortunate to have a complete set of observational and experimental data at our disposal. When some data is absent, we are allowed to discard arguments to \(\max\) or \(\min\) in (5) that depend on that data. For example, if we lack all experimental data, the only applicable lower bound in (5) is \(0\) and the only applicable upper bound is \(P(t, y) + P(c, y’)\):
Naturally, these are far more loose than the point estimates when combined experimental and observational data is fully available. Let’s similarly examine what can be computed with purely experimental data. Without observational data, only the first two arguments to \(\max\) of the lower bound and \(\min\) of the upper bound of \(P(\text{benefit})\) in (5) are applicable:
Again, these are fairly loose bounds, especially when compared to the point estimates obtained with combined data. Notice that the overlap between the female bounds using observational data, \(0 \leqslant P(\text{benefit}|\text{female}) \leqslant 0.279\), and the female bounds using experimental data, \(0.279 \leqslant P(\text{benefit}|\text{female}) \leqslant 0.489\) is the point estimate \(P(\text{benefit}|\text{female}) = 0.279\). The more comprehensive Tian-Pearl bounds formula (5) wasn’t necessary. However, the intersection of the male bounds using observational data, \(0 \leqslant P(\text{benefit}|\text{male}) \leqslant 0.58\), and the male bounds using experimental data, \(0.28 \leqslant P(\text{benefit}|\text{male}) \leqslant 0.49\), does not provide us with narrower bounds. For males, the comprehensive Tian-Pearl bounds in (5) was necessary for narrow bounds (in this case, a point estimate).
Having seen this mechanism of combining observational and experimental data in (5) work so well, the reader may ask what’s behind this? The intuition comes from the fact that observational data incorporates individuals’ whims. Whimsy is a proxy for much deeper behavior. This leads to confounding, which is ordinarily problematic for causal inference and leads to spurious conclusions, sometimes completely reversing a treatment’s effect (Pearl, 2014). Confounding then needs to be adjusted for. However, here confounding helps us, exposing the underlying mechanisms its associated whims and desires are a proxy for.
Finally, as noted in Section 3, knowing the relative sizes of the benefiting vs harmed subpopulations demands investment in finding mechanisms responsible for the differences as well as characterizations of those subpopulations. For example, women above a certain age may be affected differently by the drug, to be detected by how age affects the bounds on the individual response. Such characteristics can potentially be narrowed repeatedly until the drug’s efficacy can be predicted for an individual with certainty or the underlying mechanisms of the drug can be fully understood.
None of this was possible with only the RCT. Yet, remarkably, an observational study, however sloppy and uncontrolled, provides a deeper perspective on a treatment’s effectiveness. It incorporates individuals’ whims and desires that govern behavior under free-choice settings. And, since such whims and desires are often proxies for factors that also affect outcomes and treatments (i.e., confounders), we gain additional insight hidden by RCTs.
Footnote
2
\(P(y_t|\text{female})\) was rounded up from \(48.9\%\) to \(49\%\). The \(0.001\) difference between \(P(y_t|\text{female}\)) and \(P(y_t|\text{male})\) wasn’t necessary, but was constructed to allow for clean point estimates.
3
To simplify matters, we are treating each experimental study data as an ideal RCT, with \(100\%\) compliance and no selection bias or any other biases that can often plague RCTs.
4
Tian and Pearl (Tian and Pearl, 2000) called \(P(\text{benefit})\) “Probability of Necessity and Sufficiency” (PNS). The relationship between PNS and ICE (1) is explicated in Section 5
5
Consistency is a property imposed at the individual level, often written as
$$\begin{equation*}
Y = X \cdot Y(1) + (1-X) \cdot Y(0)
\end{equation*}$$
for binary X and Y. Rubin (Rubin, 1974) considered consistency to be an assumption in SUTVA, which defines the potential outcome (PO) framework. Pearl (Pearl, 2010) considered consistency to be a theorem of Structural Equation Models.
Annotated Bibliography for Related Works
The following is a list of papers that analyze probabilities of causation and lead to the results reported above.
Chapter 9 of Causality (Pearl, 2009) derives bounds on individual-level probabilities of causation and discusses their ramifications in legal settings. It also demonstrates how the bounds collapse to point estimates under certain combinations of observational and experimental data.
(Tian and Pearl, 2000) develops bounds on individual level causation by combining data from experimental and observational studies. This includes Probability of Sufficiency (PS), Probability of Necessity (PN), and Probability of Necessity and Sufficiency (PNS). PNS is equivalent to \(P(\text{benefit})\) above. \(\text{PNS}(u) = P(\text{benefit}|u)\), the probability that individual \(U=u\) survives if treated and does not survive if not treated, is related to \(\text{ICE}(u)\) (1) via the equation:
$$\begin{equation}
\text{PNS}(u) = P(\text{ICE}(u’) > 0 | C(u’) = C(u)).
\end{equation}$$
In words, \(\text{PNS}(u)\) equals the proportion of units \(u’\) sharing the characteristics of \(u\) that would positively benefit from the treatment. The reason is as follows. Recall that (for binary variables) \(\text{ICE}(u)\) is \(1\) when the individual benefits from the treatment, \(\text{ICE}(u)\) is \(0\) when the individual responds the same to either treatment, and \(\text{ICE}(u)\) is \(-1\) when the individual is harmed by treatment. Thus, for any given population, \(\text{PNS} = P(\text{ICE}(u) > 0)\). Focusing on the sub-population of individuals \(u’\) that share the characteristics of \(u\), \(C(u’) = C(u)\), we obtain (10). In words, \(\text{PNS}(u)\) is the fraction of indistinguishable individuals that would benefit from treatment. Note that whereas (2) is can be estimated by controlled experiments over the population \(C(u’)=C(u)\), (10) is defined counterfactually, hence, it cannot be estimated solely by such experiments; it requires additional ingredients as described in the text below.
(Mueller and Pearl, 2020) provides an interactive visualization of individual level causation, allowing readers to observe the dynamics of the bounds as one changes the available data.
(Li and Pearl, 2019) optimizes societal benefit of selecting a unit \(u\), when provided costs associated with the four different types of individuals, benefiting, harmed, always surviving, and doomed.
(Mueller et al., 2021) takes into account the causal graph to obtain narrower bounds on PNS. The hypothetical study in this article was able to calculate point estimates of PNS, but often the best we can get are bounds.
(Pearl, 2015) demonstrates how combining observational and experimental data can be informative for determining Causes of Effects, namely, assessing the probability PN that one event was a necessary cause of an observed outcome.
(Dawid and Musio, 2022) analyze Causes of Effects (CoE), defined by PN, the probability that a given intervention is a necessary cause for an observed outcome. Dawid and Musio further analyze whether bounds on PN can be narrowed with data on mediators.
Conclusion
One of the least disputed mantra of causal inference is that we cannot access individual causal effects; we can observe an individual response to treatment or to no-treatment but never to both. However, our theoretical results show that we can get bounds on individual causal effects, which sometimes can be quite narrow and allow us to make accurate personalized decisions. We project therefore that these theoretical results are key for next-generation personalized decision making.
References
Dawid, A. P., & Musio, M. (2022). Effects of causes and causes of effects. Annual Review of Statistics and its Application. https://arxiv.org/pdf/2104.00119.pdf
Li, A., & Pearl, J. (2019). Unit selection based on counterfactual logic. Proceedings of the 28th International Joint Conference on Artificial Intelligence, 1793-1799.
Mueller, S., & Pearl, J. (2020). Which Patients are in Greater Need: A counterfactual analysis with reflections on COVID-19 [https://ucla.in/39Ey8sU+].
Pearl, J. (2009). Causality (Second). Cambridge University Press.
Rubin, D. B. (1974). Estimating causal effects of treatments in randomized andnonrandomized studies. Journal of Educational Psychology, 66(5), 688-701. https://doi.org/10.1037/h0037350
Tian, J., & Pearl, J. (2000). Probabilities of causation: Bounds and identification. Annals of Mathematics and Artificial Intelligence, 28(1-4), 287-313. http://ftp.cs.ucla.edu/pub/stat_ser/r271-A.pdf
On Wednesday December 23 I had the honor of participating in “AI Debate 2”, a symposium organized by Montreal AI, which brought together an impressive group of scholars to discuss the future of AI. I spoke on
“The Domestication of Causal Reasoning: Cultural and Methodological Implications,”
and the reading list I proposed as background material was:
“The Seven Tools of Causal Inference with Reflections on Machine Learning,” July 2018 https://ucla.in/2HI2yyx
2. What I would have said had I been given six (6), instead of three (3) minutes
This is the first time I am using the word “domestication” to describe what happened in causality-land in the past 3 decades. I’ve used other terms before: “democratization,” “mathematization,” or “algorithmization,” but Domestication sounds less provocative when I come to talk about the causal revolution.
What makes it a “revolution” is seeing dozens of practical and conceptional problems that only a few decades ago where thought to be metaphysical or unsolvable give way to simple mathematical solutions.
“DEEP UNDERSTANDING” is another term used here for the first time. It so happened that, while laboring to squeeze out results from causal inference engines, I came to realize that we are sitting on a gold mine, and what we are dealing with is none other but:
A computational model of a mental state that deserves the title “Deep Understanding”
“Deep Understanding” is not the nebulous concept that you probably think it is, but something that is defined formally as any system capable of covering all 3 levels of the causal hierarchy: What is – What if – Only if. More specifically: What if I see (prediction) – What if I do (intervention) – and what if acted differently (retrospection, in light of the outcomes observed).
This may sound like cheating – I take the capabilities of one system (i.e., a causal model) and I posit them as a general criterion for defining a general concept such as: “Deep Understanding.”
It isn’t cheating. Given that causal reasoning is so deeply woven into our day to day language, our thinking, our sense of justice, our humor and of course our scientific understanding, I think that it won’t be too presumptuous of me to propose that we take Causal Modeling as a testing ground of ideas on other modes of reasoning associated with “understanding.”
Specifically, causal models should provide an arena for various theories explanations, fairness, adaptation, imagination, humor, consciousness, free will, attention, and curiosity.
I also dare speculate that learning from the way causal reasoning was domesticated, would benefit researchers in other area of AI, including vision and NLP, and enable them to examine whether similar paths could be pursued to overcome obstacles that data-centric paradigms have imposed.
I would like now to say a few words on the Anti-Cultural implications of the Causal revolution. Here I refer you to my blog post, https://ucla.in/32YKcWywhere I argue that radical empiricism is a stifling culture. It lures researchers into a data-centric paradigm, according to which Data is the source of all knowledge rather than a window through which we learn about the world around us.
What I advocate is a hybrid system that supplements data with domain knowledge, commonsense constraints, culturally transmitted concepts, and most importantly, our innate causal templates that enable toddlers to quickly acquire an understanding of their toy-world environment.
It is hard to find a needle in a hay stack, it is much harder if you haven’t seen a needle before. The module we are using for causal inference gives us a picture of what the needle looks like and what you can do once you find one.
Enticed by a recent seminar on this subject, I have re-read Breiman’s influential paper and would like to share with readers a re-assessment of its contributions to the art of statistical modeling.
When the paper first appeared, in 2001, I had the impression that, although the word “cause” did not appear explicitly, Breiman was trying to distinguish data-descriptive models from models of the data-generation process, also called “causal,” “substantive,” “subject-matter,” or “structural” models. Unhappy with his over-emphasis on prediction, I was glad nevertheless that a statistician of Breiman’s standing had recognized the on-going confusion in the field, and was calling for making the distinction crisp.
Upon re-reading the paper in 2020 I have realized that the two cultures contrasted by Breiman are not descriptive vs. causal but, rather, two styles of descriptive modeling, one interpretable, the other uninterpretable. The former is exemplified by predictive regression models, and the latter by modern big-data algorithms such as deep-learning, BART, trees and forests. The former carries the potential of being interpreted as causal, the latter leaves no room for such interpretation; it describes the prediction process chosen by the analyst, not the data-generation process chosen by nature. Breiman’s main point is: If you want prediction, do prediction for its own sake and forget about the illusion of representing nature.
Breiman’s paper deserves its reputation as a forerunner of modern machine learning techniques, but falls short of telling us what we should do if we want the model to do more than just prediction, say, to extract some information about how nature works, or to guide policies and interventions. For him, accurate prediction is the ultimate measure of merit for statistical models, an objective shared by present day machine learning enterprise, which accounts for many of its limitations (https://ucla.in/2HI2yyx).
In their comments on Breiman’s paper, David Cox and Bradley Efron noticed this deficiency and wrote:
“… fit, which is broadly related to predictive success, is not the primary basis for model choice and formal methods of model choice that take no account of the broader objectives are suspect. [The broader objectives are:] to establish data descriptions that are potentially causal.” (Cox, 2001)
And Efron concurs:
“Prediction by itself is only occasionally sufficient. … Most statistical surveys have the identification of causal factors as their ultimate goal.” (Efron, 2001)
As we read Breiman’s paper today, armed with what we know about the proper symbiosis of machine learning and causal modeling, we may say that his advocacy of algorithmic prediction was justified. Once guided by a causal model for identification and bias reduction, the predictive component of our model can safely be trusted to non-interpretable algorithms. The interpretation can be accomplished separately by the causal component of our model, as demonstrated, for example, in https://ucla.in/2HI2yyx.
Separating data-fitting from interpretation, an idea that was rather innovative in 2001, has withstood the test of time.
The following is an email exchange between Ying Nian Wu (UCLA, Statistics) and Judea Pearl (UCLA, Computer Science/Statistics).
1. Ying Nian Wu to J. Pearl, October 12, 2020
Dear Judea,
I feel all models are about making predictions for future observations. The only difference is that causal model is to predict p(y|do(x)) in your notation, where the testing data (after cutting off the arrows into x by your diagram surgery) come from a different distribution than the training data, i.e., we want to extrapolate from training data to testing data (in fact, extrapolation and interpolation are relative — a simple model that can interpolate a vast range is quite extrapolative). Ultimately a machine learning model also wants to achieve extrapolative prediction, such as the so-called transfer learning and meta learning, where testing data are different from training data, or the current short-term experience (small new training data) is different from the past long-term experience (big past training data).
About learning the model from data, we can learn p(y|x), but we can also learn p(y, x) = p(y) p(x|y). We may call p(y|x) predictive, and p(x|y) (or p(y, x)) generative, and both may involve hidden variables z. The generative model can learn from data where y is often unavailable (the so-called semi-supervised learning). In fact, learning a generative model p(y, z, x) = p(z) p(y, x|z) is necessary for predicting p(y|do(x)). I am not sure if this is also related to the two cultures mentioned by Brieman. I once asked him (at a workshop at Banff, while enjoying some second-hand smoking) about the two models, and he actually preferred generative model, although in his talk, he also emphasized that a non-parametric predictive model such as forest is still interpretable in terms of assessing the influences of variables.
To digress a bit further, there is no such a thing called how nature works according to the Copenhagen interpretation of quantum physics: there must be an observer, the observer makes a measurement, and the wave function predicts the probability distribution of the measurement. As to the question of what happens when there is no observer or the observer is not observing, the answer is that such a question is irrelevant.
Even back to the classical regime where we can ask such a question, Ptolemy’s epicycle model on planet motion, Newton’s model of gravitation, and Einstein’s model of general relativity are not that different. Ptolemy’s model is actually more general and flexible (being a Fourier expansion, where the cycle on top of cycles is similar in style to the perceptron on top of perceptrons of neural network). Newton’s model is simpler, while Einstein’s model fits the data better (being equally simple but more involved in calculation). They are all illusions about how nature works, learned from the data, and intended to predict future data. Newton’s illusion is action at a distance (which he himself did not believe), while Einstein’s illusion is about bending of spacetime, which is more believable, but still an illusion nonetheless (to be superseded by a deeper illusion such as a string).
So Box is still right: all models are wrong, but some are useful. Useful in terms of making predictions, especially making extrapolative predictions. Ying Nian
2. J. Pearl to Ying Nian Wu, October 14, 2020
Dear Ying Nian, Thanks for commenting on my “Causally Colored Reflections.”
I will start from the end of your comment, where you concur with George Box that “All models are wrong, but some are useful.” I have always felt that this aphorism is painfully true but hardly useful. As one of the most quoted aphorism in statistics, it ought to have given us some clue as to what makes one model more useful than another – it doesn’t.
A taxonomy that helps decide model usefulness should tell us (at the very least) whether a given model can answer the research question we have in mind, and where the information encoded in the model comes from. Lumping all models in one category, as in “all models are about making prediction for future observations” does not provide this information. It reminds me of Don Rubin’s statement that causal inference is just a “missing data problem” which, naturally, raises the question of what problems are NOT missing data problems, say, mathematics, chess or astrology.
In contrast, the taxonomy defined by the Ladder of Causation (see https://ucla.in/2HI2yyx): 1. Association, 2. Intervention, 3. Counterfactuals, does provide such information. Merely looking at the syntax of a model one can tell whether it can answer the target research question, and where the information supporting the model should come from, be it observational studies, experimental data, or theoretical assumptions. The main claim of the Ladder (now a theorem) is that one cannot answer questions at level i unless one has information of type i or higher. For example, there is no way to answer policy related questions unless one has experimental data or assumptions about such data. As another example, I look at what you call a generative model p(y,z,x) = p(z)p(y, x|z) and I can tell right away that, no matter how smart we are, it is not sufficient for predicting p(y|do(x)).
If you doubt the usefulness of this taxonomy, just examine the amount of efforts spent (and is still being spent) by the machine learning community on the so-called “transfer learning” problem. This effort has been futile because elementary inspection of the extrapolation task tells us that it cannot be accomplished using non-experimental data, shifting or not. See https://ucla.in/2N7S0K9.
In summary, unification of research problems is helpful when it facilitates the transfer of tools across problem types. Taxonomy of research problems is helpful too; for it spares us the efforts of trying the impossible, and it tells us where we should seek the information to support our models.
Thanks again for engaging in this conversation, Judea
3. Wu to J. Pearl, October 14, 2020
Dear Judea, Thanks for the inspiring discussion. Please allow me to formulate our consensus, and I will stop at here.
Unification 1: All models are for prediction. Unification 2: All models are for the agent to plan the action. Unification 2 is deeper than Unification 1. But Unification 1 is a good precursor.
Taxonomy 1: (a) models that predict p(y|x). (b) models that predict p(y|do(x)) or (c) models that can fill in Rubin’s table. Taxonomy 2: (a) models that fit data, not necessarily make sense, only for prediction. (b) models that understand how nature works and are interpretable.
Taxonomy 1 is deeper and more precise than Taxonomy 2, thanks to the foundational work of you and Rubin. It is based on precise, well-defined, operational mathematical language and formulation.
Taxonomy 2 is useful and is often aligned with Taxonomy 1, but we need to be aware of the limitation of Taxonomy 2, which is all I want to say in my comments. Much ink has been spilled on Taxonomy 2 because of its imprecise and non-operational nature. Ying Nian
A speaker at a lecture that I have attended recently summarized the philosophy of machine learning this way: “All knowledge comes from observed data, some from direct sensory experience and some from indirect experience, transmitted to us either culturally or genetically.”
The statement was taken as self-evident by the audience, and set the stage for a lecture on how the nature of “knowledge” can be analyzed by examining patterns of conditional probabilities in the data. Naturally, it invoked no notions such as “external world,” “theory,” “data generating process,” “cause and effect,” “agency,” or “mental constructs” because, ostensibly, these notions, too, should emerge from the data if needed. In other words, whatever concepts humans invoke in interpreting data, be their origin cultural, scientific or genetic, can be traced to, and re-derived from the original sensory experience that has endowed those concepts with survival value.
Viewed from artificial intelligence perspective, this data-centric philosophy offers an attractive, if not seductive agenda for machine learning research: In order to develop human level intelligence, we should merely trace the way our ancestors did it, and simulate both genetic and cultural evolutions on a digital machine, taking as input all the data that we can possibly collect. Taken to extremes, such agenda may inspire fairly futuristic and highly ambitious scenarios: start with a simple neural network, resembling a primitive organism (say an Amoeba), let it interact with the environment, mutate and generate offsprings; given enough time, it will eventually emerge with an Einstein’s level of intellect. Indeed, ruling out sacred scriptures and divine revelation, where else could Einstein acquire his knowledge, talents and intellect if not from the stream of raw data that has impinged upon the human race since antiquities, including of course all the sensory inputs received by more primitive organisms preceding humans.
Before asking how realistic this agenda is, let us preempt the discussion with two observations:
(1) Simulated evolution, in some form or another, is indeed the leading paradigm inspiring most machine learning researchers today, especially those engaged in connectionism, deep learning and neural networks technologies which deploy model-free, statistics-based learning strategies. The impressive success of these strategies in applications such as computer vision, voice recognition and self-driving cars has stirred up hopes in the sufficiency and unlimited potentials of these strategies, eroding, at the same time, interest in model-based approaches.
(2) The intellectual roots of the data-centric agenda are deeply grounded in the empiricist branch of Western philosophy, according to which sense-experience is the ultimate source of all our concepts and knowledge, with little or no role given to “innate ideas” and “reason” as sources of knowledge (Markie, 2017). Empiricist ideas can be traced to the ancient writings of Aristotle, but have been given prominence by the British empiricists Francis Bacon, John Locke, George Berkeley and David Hume and, more recently, by philosophers such as Charles Sanders Pierce, and William James. Modern connectionism has in fact been viewed as a Triumph of Radical Empiricism over its rationalistic rivals (Buckner 2018; Lipton, 2015). It can definitely be viewed as a testing grounds in which philosophical theories about the balance between empiricism and innateness can be submitted to experimental evaluation on digital machines.
The merits of testing philosophical theories notwithstanding, I have three major reservations about the wisdom of pursuing a radical empiricist agenda for machine learning research. I will present three arguments why empiricism should be balanced with the principles of model-based science (Pearl, 2019), in which learning is guided by two sources of information: (a) data and (b) man-made models of how data are generated.
I label the three arguments: (1) Expediency, (2) Transparency and (3) Explainability and will discuss them in turns below:
1. Expediency Evolution is too slow a process (Turing, 1950), since most mutations are useless if not harmful, and waiting for natural selection to distinguish and filter the useful from the useless is often un-affordable. The bulk of machine learning tasks requires speedy interpretation of, and quick reaction to new and sparse data, too sparse to allow filtering by random mutations. The outbreak of the COVID-19 pandemic is a perfect example of a situation where sparse data, arriving from unreliable and heterogeneous sources required quick interpretation and quick action, based primarily on prior models of epidemic transmission and data production (https://ucla.in/3iEDRVo). In general, machine learning technology is expected to harness a huge amount of scientific knowledge already available, combine it with whatever data can be gathered, and solve crucial societal problems in areas such as health, education, ecology and economics.
Even more importantly, scientific knowledge can speed up evolution by actively guiding the selection or filtering of data and data sources. Choosing what data to consider or what experiments to run requires hypothetical theories of what outcomes are expected from each option, and how likely they are to improve future performance. Such expectations are provided, for example, by causal models that predict both the outcomes of hypothetical manipulations as well the consequences of counterfactual undoing of past events (Pearl, 2019).
2. Transparency World knowledge, even if evolved spontaneously from raw data, must eventually be compiled and represented in some machine form to be of any use. The purpose of compiled knowledge is to amortize the discovery process over many inference tasks without repeating the former. The compiled representation should then facilitate an efficient production of answers to select set of decision problems, including questions on ways of gathering additional data. Some representations allow for such inferences and others do not. For example, knowledge compiled as patterns of conditional probability estimates does not allow for predicting the effect of actions or policies. (Pearl, 2019).
Knowledge compilation involves both abstraction and re-formatting. The former allows for information loss (as in the case of probability models) while the latter retains the information content and merely transform some of the information from implicit to explicit representations.
These considerations demand that we study the mathematical properties of compiled representations, their inherent limitations, the kind of inferences they support, and how effective they are in producing the answers they are expected to produce. In more concrete terms, machine learning researchers should engage in what is currently called “causal modelling” and use the tools and principles of causal science to guide data exploration and data interpretation processes.
3. Explainability Regardless of how causal knowledge is accumulated, discovered or stored, the inferences enabled by that knowledge are destined to be delivered to, and benefit a human user. Today, these usages include policy evaluation, personal decisions, generating explanations, assigning credit and blame or making general sense of the world around us. All inferences must therefore be cast in a language that matches the way people organize their world knowledge, namely, the language of cause and effect. It is imperative therefore that machine learning researchers regardless of the methods they deploy for data fitting, be versed in this user-friendly language, its grammar, its universal laws and the way humans interpret or misinterpret the functions that machine learning algorithms discover.
Conclusions It is a mistake to equate the content of human knowledge with its sense-data origin. The format in which knowledge is stored in the mind (or on a computer) and, in particular, the balance between its implicit vs. explicit components are as important for its characterization as its content or origin.
While radical empiricism may be a valid model of the evolutionary process, it is a bad strategy for machine learning research. It gives a license to the data-centric thinking, currently dominating both statistics and machine learning cultures, according to which the secret to rational decisions lies in the data alone.
A hybrid strategy balancing “data-fitting” with “data-interpretation” better captures the stages of knowledge compilation that the evolutionary processes entails.
The following email exchange with Yoshua Bengio clarifies the claims and aims of the post above.
Yoshua Bengio commented Aug 3 2020 2:21 pm
Hi Judea,
Thanks for your blog post! I have a high-level comment. I will start from your statement that “learning is guided by two sources of information: (a) data and (b) man-made models of how data are generated. ” This makes sense in the kind of setting you have often discussed in your writings, where a scientist has strong structural knowledge and wants to combine it with data in order to arrive at some structural (e.g. causal) conclusions. But there are other settings where this view leaves me wanting more. For example, think about a baby before about 3 years old, before she can gather much formal knowledge of the world (simply because her linguistic abilities are not yet developed or not enough developed, not to mention her ability to consciously reason). Or think about how a chimp develops an intuitive understanding of his environment which includes cause and effect. Or about an objective to build a robot which could learn about the world without relying on human-specified theories. Or about an AI which would have as a mission to discover new concepts and theories which go well beyond those which humans provide. In all of these cases we want to study how both statistical and causal knowledge can be (jointly) discovered. Presumably this may be from observations which include changes in distribution due to interventions (our learning agent’s or those of other agents). These observations are still data, just of a richer kind than what current purely statistical models (I mean trying to capture only joint distributions or conditional distribution) are built on. Of course, we *also* need to build learning machines which can interact with humans, understand natural language, explain their decisions (and our decisions), and take advantage of what human culture has to offer. Not taking advantage of knowledge when we have it may seem silly, but (a) our presumed knowledge is sometimes wrong or incomplete, (b) we still want to understand how pre-linguistic intelligence manages to make sense of the world (including of its causal structure), and (c) forcing us into this more difficult setting could also hasten the discovery of the learning principles required to achieve (a) and (b).
Cheers and thanks again for your participation in our recent CIFAR workshop on causality!
— Yoshua
Judea Pearl reply, August 4 5:53 am
Hi Yoshua, The situation you are describing: “where a scientist has strong structural knowledge and wants to combine it with data in order to arrive at some structural (e.g. causal) conclusions” motivates only the first part of my post (labeled “expediency”). But the enterprise of causal modeling brings another resource to the table. In addition to domain specific knowledge, it brings a domain-independent “template” that houses that knowledge and which is useful for precisely the “other settings” you are aiming to handle:
“a baby before about 3 years old, before she can gather much formal knowledge of the world … Or think about how a chimp develops an intuitive understanding of his environment which includes cause and effect. Or about an objective to build a robot which could learn about the world without relying on human-specified theories.”
A baby and a chimp exposed to the same stimuli will not develop the same understanding of the world, because the former starts with a richer inborn template that permits it to organize, interpret and encode the stimuli into a more effective representation. This is the role of “compiled representations” mentioned in the second part of my post. (And by “stimuli”, I include “playful manipulations”) .
In other words, the baby’s template has a richer set of blanks to be filled than the chimp’s template, which accounts for Alison Gopnik’s finding of a greater reward-neutral curiosity in the former.
The science of Causal Modeling proposes a concrete embodiment of that universal “template”. The mathematical properties of the template, its inherent limitations and inferential and algorithmic capabilities should therefore be studied by every machine learning researcher, regardless of whether she obtains it from domain expert or discovers it on her own from invariant features of the data.
Finding a needle in a haystack is difficult, and it’s close to impossible if you haven’t seen a needle before. Most ML researchers today have not seen a needle — an educational gap that needs to be corrected in order to hasten the discovery of those learning principles you aspire to uncover.
Cheers and thanks for inviting me to participate in your CIFAR workshop on causality.
— Judea
Yoshua Bengio comment Aug. 4, 7:00 am
Agreed. What you call the ‘template’ is something I sort in the machine learning category of ‘inductive biases’ which can be fairly general and allow us to efficiently learn (and here discover representations which build a causal understanding of the world).
Summary The post below is written for the upcoming Spanish translation of The Book of Why, which was announced today. It expresses my firm belief that the current data-fitting direction taken by “Data Science” is temporary (read my lips!), that the future of “Data Science” lies in causal data interpretation and that we should prepare ourselves for the backlash swing.
Data versus Science: Contesting the Soul of Data-Science Much has been said about how ill-prepared our health-care system was in coping with catastrophic outbreaks like COVID-19. Yet viewed from the corner of my expertise, the ill-preparedness can also be seen as a failure of information technology to keep track of and interpret the outpour of data that have arrived from multiple and conflicting sources, corrupted by noise and omission, some by sloppy collection and some by deliberate misreporting, AI could and should have equipped society with intelligent data-fusion technology, to interpret such conflicting pieces of information and reason its way out of the confusion.
Speaking from the perspective of causal inference research, I have been part of a team that has developed a complete theoretical underpinning for such “data-fusion” problems; a development that is briefly described in Chapter 10 of The Book of Why. A system based on data fusion principles should be able to attribute disparities between Italy and China to differences in political leadership, reliability of tests and honesty in reporting, adjust for such differences and automatically infer behavior in countries like Spain or the US. AI is in a position to to add such data-interpreting capabilities on top of the data-fitting technologies currently in use and, recognizing that data are noisy, filter the noise and outsmart the noise makers.
“Data fitting” is the name I frequently use to characterize the data-centric thinking that dominates both statistics and machine learning cultures, in contrast to the “data-interpretation” thinking that guides causal inference. The data-fitting school is driven by the faith that the secret to rational decisions lies in the data itself, if only we are sufficiently clever at data mining. In contrast, the data-interpreting school views data, not as a sole object of inquiry but as an auxiliary means for interpreting reality, and “reality” stands for the processes that generate the data.
I am not alone in this assessment. Leading researchers in the “Data Science” enterprise have come to realize that machine learning as it is currently practiced cannot yield the kind of understanding that intelligent decision making requires. However, what many fail to realize is that the transition from data-fitting to data-understanding involves more than a technology transfer; it entails a profound paradigm shift that is traumatic if not impossible. Researchers whose entire productive career have committed them to the supposition that all knowledge comes from the data cannot easily transfer allegiance to a totally alien paradigm, according to which extra-data information is needed, in the form of man-made, causal models of reality. Current machine learning thinking, which some describe as “statistics on steroids,” is deeply entrenched in this self-propelled ideology.
Ten years from now, historians will be asking: How could scientific leaders of the time allow society to invest almost all its educational and financial resources in data-fitting technologies and so little on data-interpretation science? The Book of Why attempts to answer this dilemma by drawing parallels to historically similar situations where ideological impediments held back scientific progress. But the true answer, and the magnitude of its ramifications, will only be unravelled by in-depth archival studies of the social, psychological and economical forces that are currently governing our scientific institutions.
A related, yet perhaps more critical topic that came up in handling the COVID-19 pandemic, is the issue of personalized care. Much of current health-care methods and procedures are guided by population data, obtained from controlled experiments or observational studies. However, the task of going from these data to the level of individual behavior requires counterfactual logic, which has been formalized and algorithmatized in the past 2 decades (as narrated in Chapter 8 of The Book of Why), and is still a mystery to most machine learning researchers.
The immediate area where this development could have assisted the COVID-19 pandemic predicament concerns the question of prioritizing patients who are in “greatest need” for treatment, testing, or other scarce resources. “Need” is a counterfactual notion (i.e., patients who would have gotten worse had they not been treated) and cannot be captured by statistical methods alone. A recently posted blog page https://ucla.in/39Ey8sU demonstrates in vivid colors how counterfactual analysis handles this prioritization problem.
The entire enterprise known as “personalized medicine” and, more generally, any enterprise requiring inference from populations to individuals, rests on counterfactual analysis, and AI now holds the key theoretical tools for operationalizing this analysis.
People ask me why these capabilities are not part of the standard tool sets available for handling health-care management. The answer lies again in training and education. We have been rushing too eagerly to reap the low-lying fruits of big data and data fitting technologies, at the cost of neglecting data-interpretation technologies. Data-fitting is addictive, and building more “data-science centers” only intensifies the addiction. Society is waiting for visionary leadership to balance this over-indulgence by establishing research, educational and training centers dedicated to “causal science.”
I hope it happens soon, for we must be prepared for the next pandemic outbreak and the information confusion that will probably come in its wake.
This post reports on the presence of Simpson’s paradox in the latest CDC data on coronavirus. At first glance, the data may seem to support the notion that coronavirus is especially dangerous to white, non-Hispanic people. However, when we take into account the causal structure of the data, and most importantly we think about what causal question we want to answer, the conclusion is quite different. This gives us an opportunity to emphasize a point that was perhaps not stressed enough in The Book of Why, namely that formulation of the right query is just as important as constructing the right causal model.
Race, COVID Mortality, and Simpson’s Paradox
Recently I was perusing the latest data on coronavirus on the Centers for Disease Control (CDC) website. When I got to the two graphs shown below, I did a double-take.
(click on the graph to enlarge)
COVID-19 Cases and Deaths by Race and Ethnicity (CDC, 6/30/2020).
This is a lot to take in, so let me point out what shocked me. The first figure shows that 35.3 percent of diagnosed COVID cases were in “white, non-Hispanic” people. But 49.5 percent of COVID deaths occurred to people in this category. In other words, whites who have been diagnosed as COVID-positive have a 40 percent greater risk of death than non-whites or Hispanics who have been diagnosed as COVID-positive.
This, of course, is the exact opposite of what we have been hearing in the news media. (For example, Graeme Wood in The Atlantic: “Black people die of COVID-19 at a higher rate than white people do.”) Have we been victimized by a media deception? The answer is NO, but the explanation underscores the importance of understanding the causal structure of data and interrogating that data using properly phrased causal queries.
Let me explain, first, why the data above cannot be taken at face value. The elephant in the room is age, which is the single biggest risk factor for death due to COVID-19. Let’s look at the CDC mortality data again, but this time stratifying by age group.
Race →
White, non-Hispanic
Others
Age ↓
Cases
Deaths
Cases
Deaths
0-4
23.9%
53.3%
76.1%
46.7%
5-17
19%
9.1%
81%
90.9%
18-29
29.8%
18.9%
70.2%
81.1%
30-39
26.5%
16.4%
73.5%
83.6%
40-49
26.5%
16.4%
73.5%
83.6%
50-64
36.4%
16.4%
63.6%
83.6%
65-74
45.9%
40.8%
54.1%
59.2%
75-84
55.4%
52.1%
44.6%
47.9%
85+
69.6%
67.6%
30.4%
32.4%
ALL AGES
35.4%
49.5%
64.6%
50.5%
This table shows us that in every age category (except ages 0-4), whites have a lower case fatality rate than non-whites. That is, whites make up a lower percentage of deaths than cases. But when we aggregate all of the ages, whites have a higher fatality rate. The reason is simple: whites are older.
According to U.S. census data (not shown here), 9 percent of the white population in the United States is over age 75. By comparison, only 4 percent of Black people and 3 percent of Hispanic people have reached the three-quarter-century mark. People over age 75 are exactly the ones who are at greatest risk of dying from COVID (and by a wide margin). Thus the white population contains more than twice as many high-risk people as the Black population, and three times as many high-risk people as the Hispanic population.
People who have taken a course in statistics may recognize the phenomenon we have uncovered here as Simpson’s paradox. To put it most succinctly, and most paradoxically, if you tell me that you are white and COVID-positive, but do not tell me your age, I have to assume you have a higher risk of dying than your neighbor who is Black and COVID-positive. But if you do tell me your age, your risk of dying becomes less than your neighbor who is Black and COVID-positive and the same age. How can that be? Surely the act of telling me your age should not make any difference to your medical condition.
In introductory statistics courses, Simpson’s paradox is usually presented as a curiosity, but the COVID data shows that it raises a fundamental question. Which is a more accurate picture of reality? The one where I look only at the aggregate data and conclude that whites are at greater risk of dying, or the one where I break the data down by age and conclude that non-whites are at greater risk?
The general answer espoused by introductory statistics textbooks is: control for everything. If you have age data, stratify by age. If you have data on underlying medical conditions, or socioeconomic status, or anything else, stratify by those variables too.
This “one-size-fits-all” approach is misguided because it ignores the causal story behind the data. In The Book of Why, we look at a fictional example of a drug that is intended to prevent heart attacks by lowering blood pressure. We can summarize the causal story in a diagram:
Here blood pressure is what we call a mediator, an intervening variable through which the intervention produces its effect. We also allow for the possibility that the drug may directly influence the chances of a heart attack in other, unknown ways, by drawing an arrow directly from “Drug” to “Heart Attack.”
The diagram tells us how to interrogate the data. Because we want to know the drug’s total effect on the patient, through the intended route as well as other, unintended routes, we should not stratify the data. That is, we should not separate the experimental data into “high-blood-pressure” and “low-blood-pressure” groups. In our book, we give (fictitious) experimental data in which the drug increases the risk of heart attack among people in the low-blood-pressure group and among people in the high-blood-pressure group (presumably because of side effects). But at the same time, and most importantly, it shifts patients from the high-risk high-blood-pressure group into the low-risk low-blood-pressure group. Thus its total effect is beneficial, even though its effect on each stratum appears to be harmful.
It’s interesting to compare this fictitious example to the all-too-real COVID example, which I would argue has a very similar causal structure:
The causal arrow from “race” to “age” means that your race influences your chances of living to age 75 or older. In this diagram, Age is a mediator between Race and Death from COVID; that is, it is a mechanism through which Race acts. As we saw in the data, it’s quite a potent mechanism; in fact, it accounts for why white people who are COVID-positive die more often.
Because the two causal diagrams are the same, you might think that in the second case, too, we should not stratify the data; instead we should use the aggregate data and conclude that COVID is a disease that “discriminates” against whites.
However, this argument ignores the second key ingredient I mentioned earlier: interrogating the data using correctly phrased causal queries.
What is our query in this case? It’s different from what it was in the drug example. In that case, we were looking at the drug as a preventative for a heart attack. If we were to look at the COVID data in the same way, we would ask, “What is the total lifetime effect of intervening (before birth) to change a person’s race?” And yes: if we could perform that intervention, and if our sole objective was to prevent death from COVID, we would choose to change our race from white to non-white. The “benefit” of that intervention would be that we would never live to an age where we were at high risk of dying from COVID.
I’m sure you can see, without my even explaining it, that this is not the query any reasonable person would pose. “Saving” lives from COVID by making them end earlier for other reasons is not a justifiable health policy.
Thus, the query we want to interrogate the data with is not “What is the total effect?” but “What is the direct effect?” As we explain on page 312 of The Book of Why, this is always the query we are interested in when we talk about discrimination. If we want to know whether our health-care system discriminates against a certain ethnic group, then we want to hold all other variables constant that might account for the outcome, and see what is the effect of changing Race alone. In this case, that means stratifying the data by Age, and the result is that we do see evidence of discrimination. Non-whites do worse at (almost) every age. As Wood writes, “The virus knows no race or nationality; it can’t peek at your driver’s license or census form to check whether you are black. Society checks for it, and provides the discrimination on the virus’s behalf.”
To reiterate: The causal story here is identical to the Drug-Blood Pressure-Heart Attack example. What has changed is our query. Precision is required both in formulating the causal model, and in deciding what is the question we want to ask of it.
I wanted to place special emphasis on the query because I recently was asked to referee an article about Simpson’s paradox that missed this exact point. Of course I cannot tell you more about the author or the journal. (I don’t even know who the author is.) It was a good article overall, and I hope that it will be published with a suitable revision.
In the meantime, there is plenty of room for further exploration of the coronavirus epidemic with causal models. Undoubtedly the diagram above is too simple; unfortunately, if we make it more realistic by including more variables, we may not have any data available to interrogate. In fact, even in this case there is a huge amount of missing data: 51 percent of the COVID cases have unknown race/ethnicity, and 19 percent of the deaths. Thus, while we can learn an excellent lesson about Simpson’s paradox and some probable lessons about racial inequities, we have to present the results with some caution. Finally, I would like to draw attention to something curious in the CDC data: The case fatality rate for whites in the youngest age group, ages 0-4, is much higher than for non-whites. I don’t know how to explain this, and I would think that someone with an interest in pediatric COVID cases should investigate.
I was privileged to be interviewed recently by David Hand, Professor of Statistics at Imperial College, London, and a former President of the Royal Statistical Society. I would like to share this interview with readers of this blog since many of the questions raised by David keep coming up in my conversations with statisticians and machine learning researchers, both privately and on Twitter.
For me, David represents mainstream statistics and, the reason I find his perspective so valuable is that he does not have a stake in causality and its various formulations. Like most mainstream statisticians, he is simply curious to understand what the big fuss is all about and how to communicate differences among various approaches without taking sides.
So, I’ll let David start, and I hope you find it useful.
Judea Pearl Interview by David Hand
There are some areas of statistics which seem to attract controversy and disagreement, and causal modelling is certainly one of them. In an attempt to understand what all the fuss is about, I asked Judea Pearl about these differences in perspective. Pearl is a world leader in the scientific understanding of causality. He is a recipient of the AMC Turing Award (computing’s “Nobel Prize”), for “fundamental contributions to artificial intelligence through the development of a calculus for probabilistic and causal reasoning”, the David E. Rumelhart Prize for Contributions to the Theoretical Foundations of Human Cognition, and is a Fellow of the American Statistical Association.
QUESTION 1:
I am aware that causal modelling is a hotly contested topic, and that there are alternatives to your perspective – the work of statisticians Don Rubin and Phil Dawid spring to mind, for example. Words like counterfactual, Popperian falsifiability, potential outcomes, appear. I’d like to understand the key differences between the various perspectives, so can you tell me what are the main grounds on which they disagree?
ANSWER 1:
You might be surprised to hear that, despite what seems to be hotly contested debates, there are very few philosophical differences among the various “approaches.” And I put “approaches” in quotes because the differences are more among historical traditions, or “frameworks” than among scientific principles. If we compare, for example, Rubin’s potential outcome with my framework, named “Structural Causal Models” (SCM), we find that the two are logically equivalent; a theorem in one is a theorem in the other and an assumption in one can be written as an assumption in the other. This means that, starting with the same set of assumptions, every solution obtained in one can also be obtained in the other.
But logical equivalence does not means “modeling equivalence” when we consider issues such as transparency, credibility or tractability. The equations for straight lines in polar coordinates are equivalent to those in Cartesian coordinates yet are hardly manageable when it comes to calculating areas of squares or triangles.
In SCM, assumptions are articulated in the form of equations among measured variables, each asserting how one variable responds to changes in another. Graphical models are simple abstractions of those equations and, remarkably, are sufficient for answering many causal questions when applied to non-experimental data. An arrow X—>Y in a graphical model represents the capacity to respond to such changes. All causal relationships are derived mechanically from those qualitative primitives, demanding no further judgment of the modeller.
In Rubin’s framework, assumptions are expressed as conditional independencies among counterfactual variables, also known as “ignorability conditions.” The mental task of ascertaining the plausibility of such assumptions is beyond anyone’s capacity, which makes it extremely hard for researchers to articulate or to verify. For example, the task of deciding which measurements to include in the analysis (or in the propensity score) is intractable in the language of conditional ignorability. Judging whether the assumptions are compatible with the available data, is another task that is trivial in graphical models and insurmountable in the potential outcome framework.
Conceptually, the differences can be summarized thus: The graphical approach goes where scientific knowledge resides, while Rubin’s approach goes where statistical routines need to be justified. The difference shines through when simple problems are solved side by side in both approaches, as in my book Causality (2009). The main reason differences between approaches are still debated in the literature is that most statisticians are watching these debates as outsiders, instead of trying out simple examples from beginning to end. Take for example Simpson’s paradox, a puzzle that has intrigued a century of statisticians and philosophers. It is still as vexing to most statisticians today as it was to Pearson in 1889, and the task of deciding which data to consult, the aggregated or the disaggregated is still avoided by all statistics textbooks.
To summarize, causal modeling, a topic that should be of prime interest to all statisticians, is still perceived to be a “hotly contested topic”, rather than the main frontier of statistical research. The emphasis on “differences between the various perspectives” prevents statisticians from seeing the exciting new capabilities that now avail themselves, and which “enable us to answer questions that we have always wanted but were afraid to ask.” It is hard to tell whether fears of those “differences” prevent statisticians from seeing the excitement, or the other way around, and cultural inhibitions prevent statisticians from appreciating the excitement, and drive them to discuss “differences” instead.
QUESTION 2:
There are different schools of statistics, but I think that most modern pragmatic applied statisticians are rather eclectic, and will choose a method which has the best capability to answer their particular questions. Does the same apply to approaches to causal modelling? That is, do the different perspectives have strengths and weaknesses, and should we be flexible in our choice of approach?
ANSWER 2:
These strengths and weaknesses are seen clearly in the SCM framework, which unifies several approaches and provides a flexible way of leveraging the merits of each. In particular, SCM combines graphical models and potential outcome logic. The graphs are used to encode what we know (i.e., the assumptions we are willing to defend) and the logic is used to encode what we wish to know, that is, the research question of interest. Simple mathematical tools can then combine these two with data and produce consistent estimates.
The availability of these unifying tools now calls on statisticians to become actively involved in causal analysis, rather than attempting to judge approaches from a distance. The choice of approach will become obvious once research questions are asked and the stage is set to articulate subject matter information that is necessary in answering those questions.
QUESTION 3:
To a very great extent the modern big data revolution has been driven by so-called “databased” models and algorithms, where understanding is not necessarily relevant or even helpful, and where there is often no underlying theory about how the variables are related. Rather, the aim is simply to use data to construct a model or algorithm which will predict an outcome from input variables (deep learning neural networks being an illustration). But this approach is intrinsically fragile, relying on an assumption that the data properly represent the population of interest. Causal modelling seems to me to be at the opposite end of the spectrum: it is intrinsically “theory-based”, because it has to begin with a causal model. In your approach, described in an accessible way in your recent book The Book of Why, such models are nicely summarised by your arrow charts. But don’t theory-based models have the complementary risk that they rely heavily on the accuracy of the model? As you say on page 160 of The Book of Why, “provided the model is correct”.
ANSWER 3:
When the tasks are purely predictive, model-based methods are indeed not immediately necessary and deep neural networks perform surprisingly well. This is level-1 (associational) in the Ladder of Causation described in The Book of Why. In tasks involving interventions, however (level-2 of the Ladder), model-based methods become a necessity. There is no way to predict the effect of policy interventions (or treatments) unless we are in possession of either causal assumptions or controlled randomized experiments employing identical interventions. In such tasks, and absent controlled experiments, reliance on the accuracy of the model is inevitable, and the best we can do is to make the model transparent, so that its accuracy can be (1) tested for compatibility with data and/or (2) judged by experts as well as policy makers and/or (3) subjected to sensitivity analysis.
A major reason why statisticians are reluctant to state and rely on untestable modeling assumptions stems from lack of training in managing such assumptions, however plausible. Even stating such unassailable assumptions as “symptoms do not cause diseases” or “drugs do not change patient’s sex” require a vocabulary that is not familiar to the great majority of living statisticians. Things become worse in the potential outcome framework where such assumptions resist intuitive interpretation, let alone judgment of plausibility. It is important at this point to go back and qualify my assertion that causal models are not necessary for purely predictive tasks. Many tasks that, at first glance appear to be predictive, turn out to require causal analysis. A simple example is the problem of external validity or inference across populations. Differences among populations are very similar to differences induced by interventions, hence methods of transporting information from one population to another can leverage all the tools developed for predicting effects of interventions. A similar transfer applies to missing data analysis, traditionally considered a statistical problem. Not so. It is inherently a causal problem since modeling the reason for missingness is crucial for deciding how we can recover from missing data. Indeed modern methods of missing data analysis, employing causal diagrams are able to recover statistical and causal relationships that purely statistical methods have failed to recover.
QUESTION 4:
In a related vein, the “backdoor” and “frontdoor” adjustments and criteria described in the book are very elegant ways of extracting causal information from arrow diagrams. They permit causal information to be obtained from observational data. Provided that is, the arrow diagram accurately represents the relationships between all the relevant variables. So doesn’t valid application of this elegant calculus depends critically on the accuracy of the base diagram?
ANSWER 4:
Of course. But as we have agreed above, EVERY exercise in causal inference “depends critically on the accuracy” of the theoretical assumptions we make. Our choice is whether to make these assumptions transparent, namely, in a form that allows us to scrutinize their veracity, or bury those assumptions in cryptic notation that prevents scrutiny.
In a similar vein, I must modify your opening statement, which described the “backdoor” and “frontdoor” criteria as “elegant ways of extracting causal information from arrow diagrams.” A more accurate description would be “…extracting causal information from rudimentary scientific knowledge.” The diagrammatic description of these criteria enhances, rather than restricts their range of applicability. What these criteria in fact do is extract quantitative causal information from conceptual understanding of the world; arrow diagrams simply represent the extent to which one has or does not have such understanding. Avoiding graphs conceals what knowledge one has, as well as what doubts one entertains.
QUESTION 5:
You say, in The Book of Why (p5-6) that the development of statistics led it to focus “exclusively on how to summarise data, not on how to interpret it.” It’s certainly true that when the Royal Statistical Society was established it focused on “procuring, arranging, and publishing ‘Facts calculated to illustrate the Condition and Prospects of Society’,” and said that “the first and most essential rule of its conduct [will be] to exclude carefully all Opinions from its transactions and publications.” But that was in the 1830s, and things have moved on since then. Indeed, to take one example, clinical trials were developed in the first half of the Twentieth Century and have a history stretching back even further. The discipline might have been slow to get off the ground in tackling causal matters, but surely things have changed and a very great deal of modern statistics is directly concerned with causal matters – think of risk factors in epidemiology or manipulation in experiments, for example. So aren’t you being a little unfair to the modern discipline?
ANSWER 5:
Ronald Fisher’s manifesto, in which he pronounced that “the object of statistical methods is the reduction of data” was published in 1922, not in the 19th century (Fisher 1922). Data produced in clinical trials have been the only data that statisticians recognize as legitimate carriers of causal information, and our book devotes a whole chapter to this development. With the exception of this singularity, however, the bulk of mainstream statistics has been glaringly disinterested in causal matters. And I base this observation on three faithful indicators: statistics textbooks, curricula at major statistics departments, and published texts of Presidential Addresses in the past two decades. None of these sources can convince us that causality is central to statistics.
Take any book on the history of statistics, and check if it considers causal analysis to be of primary concern to the leading players in 20th century statistics. For example, Stigler’s The Seven Pillars of Statistical Wisdom (2016) barely makes a passing remark to two (hardly known) publications in causal analysis.
I am glad you mentioned epidemiologists’ analysis of risk factors as an example of modern interest in causal questions. Unfortunately, epidemiology is not representative of modern statistics. In fact epidemiology is the one field where causal diagrams have become a second language, contrary to mainstream statistics, where causal diagrams are still a taboo. (e.g., Efron and Hastie 2016; Gelman and Hill, 2007; Imbens and Rubin 2015; Witte and Witte, 2017).
When an academic colleague asks me “Aren’t you being a little unfair to our discipline, considering the work of so and so?”, my answer is “Must we speculate on what ‘so and so’ did? Can we discuss the causal question that YOU have addressed in class in the past year?” The conversation immediately turns realistic.
QUESTION 6:
Isn’t the notion of intervening through randomisation still the gold standard for establishing causality?
ANSWER 6:
It is. Although in practice, the hegemony of randomized trial is being contested by alternatives. Randomized trials suffer from incurable problems such as selection bias (recruited subject are rarely representative of the target population) and lack of transportability (results are not applicable when populations change). The new calculus of causation helps us overcome these problems, thus achieving greater over all credibility; after all, observational studies are conducted at the natural habitat of the target population.
QUESTION 7:
What would you say are the three most important ideas in your approach? And what, in particular, would you like readers of The Book of Why to take away from the book.
ANSWER 7:
The three most important ideas in the book are: (1) Causal analysis is easy, but requires causal assumptions (or experiments) and those assumptions require a new mathematical notation, and a new calculus. (2) The Ladder of Causation, consisting of (i) association (ii) interventions and (iii) counterfactuals, is the Rosetta Stone of causal analysis. To answer a question at layer (x) we must have assumptions at level (x) or higher. (3) Counterfactuals emerge organically from basic scientific knowledge and, when represented in graphs, yield transparency, testability and a powerful calculus of cause and effect. I must add a fourth take away: (4) To appreciate what modern causal analysis can do for you, solve one toy problem from beginning to end; it would tell you more about statistics and causality than dozens of scholarly articles laboring to overview statistics and causality.
REFERENCES
Efron, B. and Hastie, T., Computer Age Statistical Inference: Algorithms, Evidence, and Data Science, New York, NY: Cambridge University Press, 2016.
Fisher, R., “On the mathematical foundations of theoretical statistics,” Philosophical Transactions of the Royal Society of London, Series A 222, 311, 1922.
Gelman, A. and Hill, J., Data Analysis Using Regression and Multilevel/Hierarchical Models, New York: Cambridge University Press, 2007.
Imbens, G.W. and Rubin, D.B., Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction, Cambridge, MA: Cambridge University Press, 2015.
Witte, R.S. and Witte, J.S., Statistics, 11th edition, Hoboken, NJ: John Wiley & Sons, Inc. 2017.
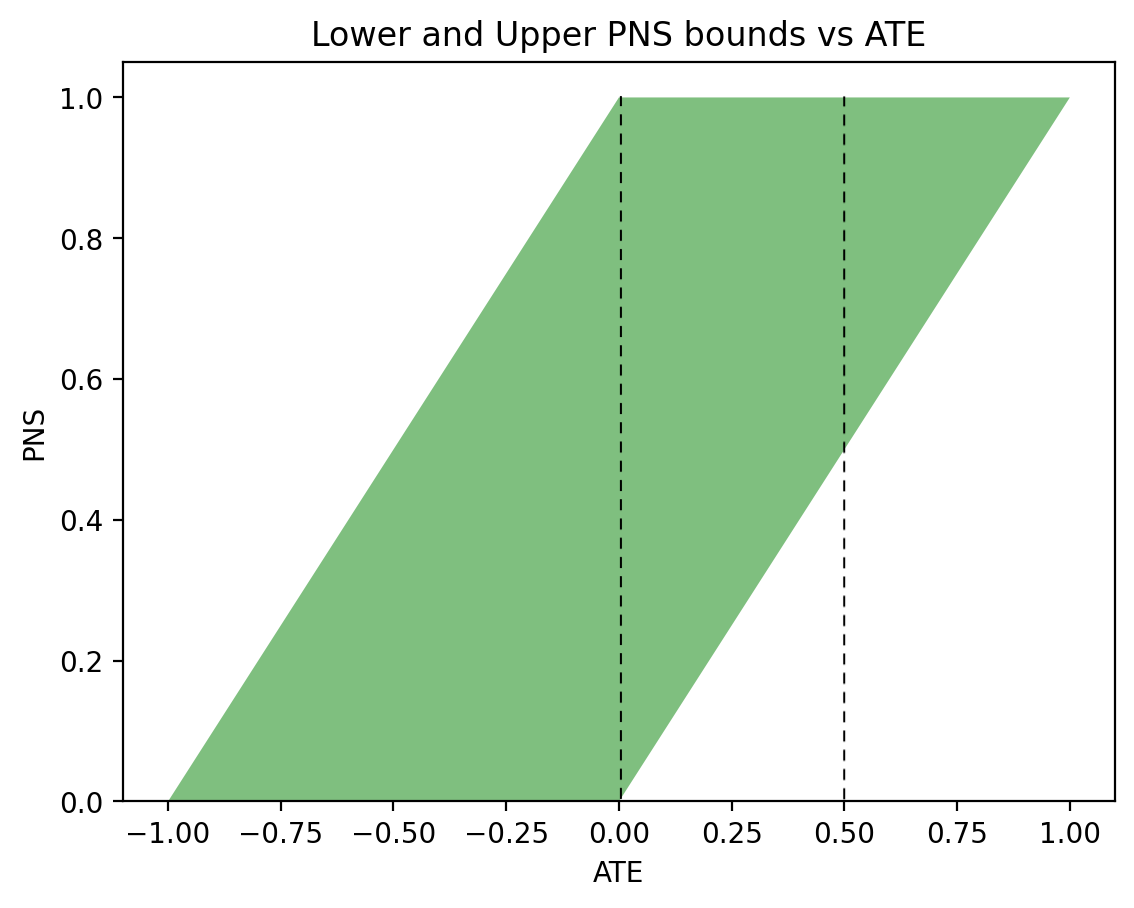
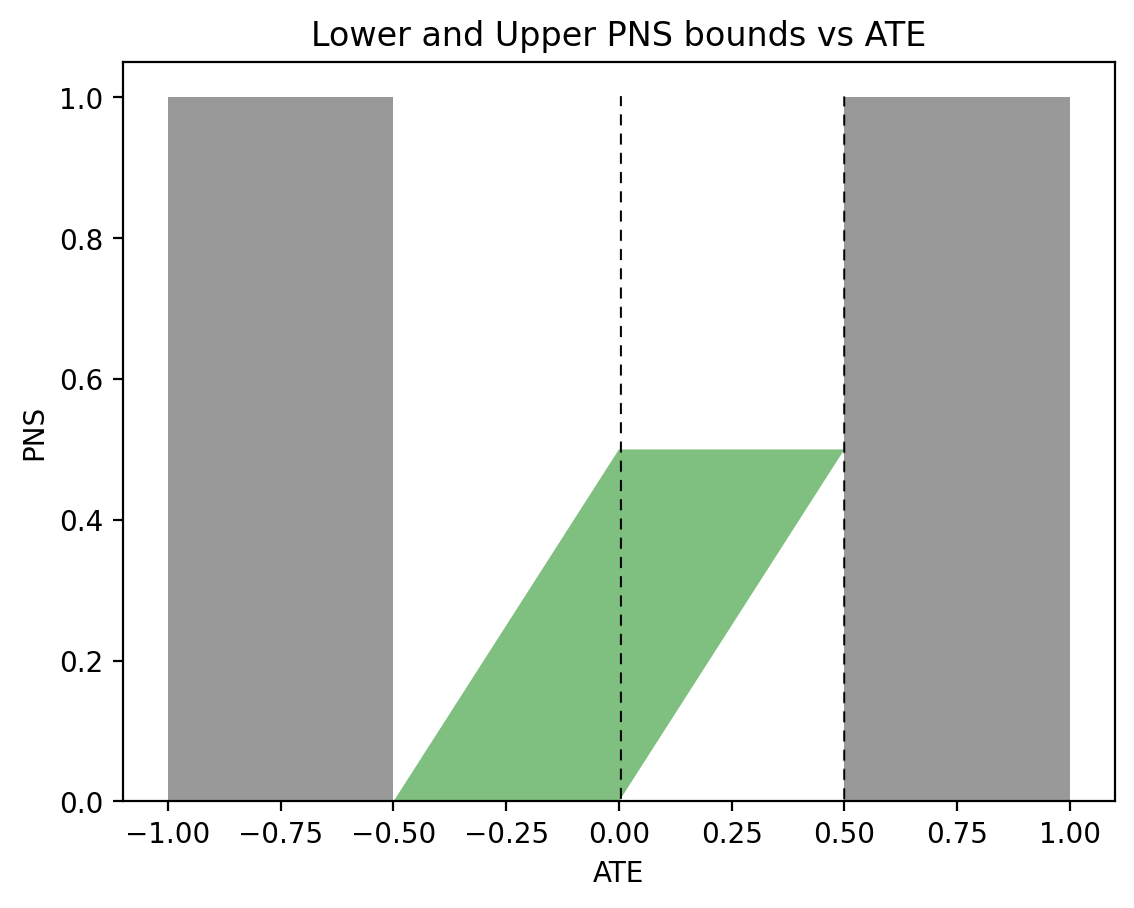
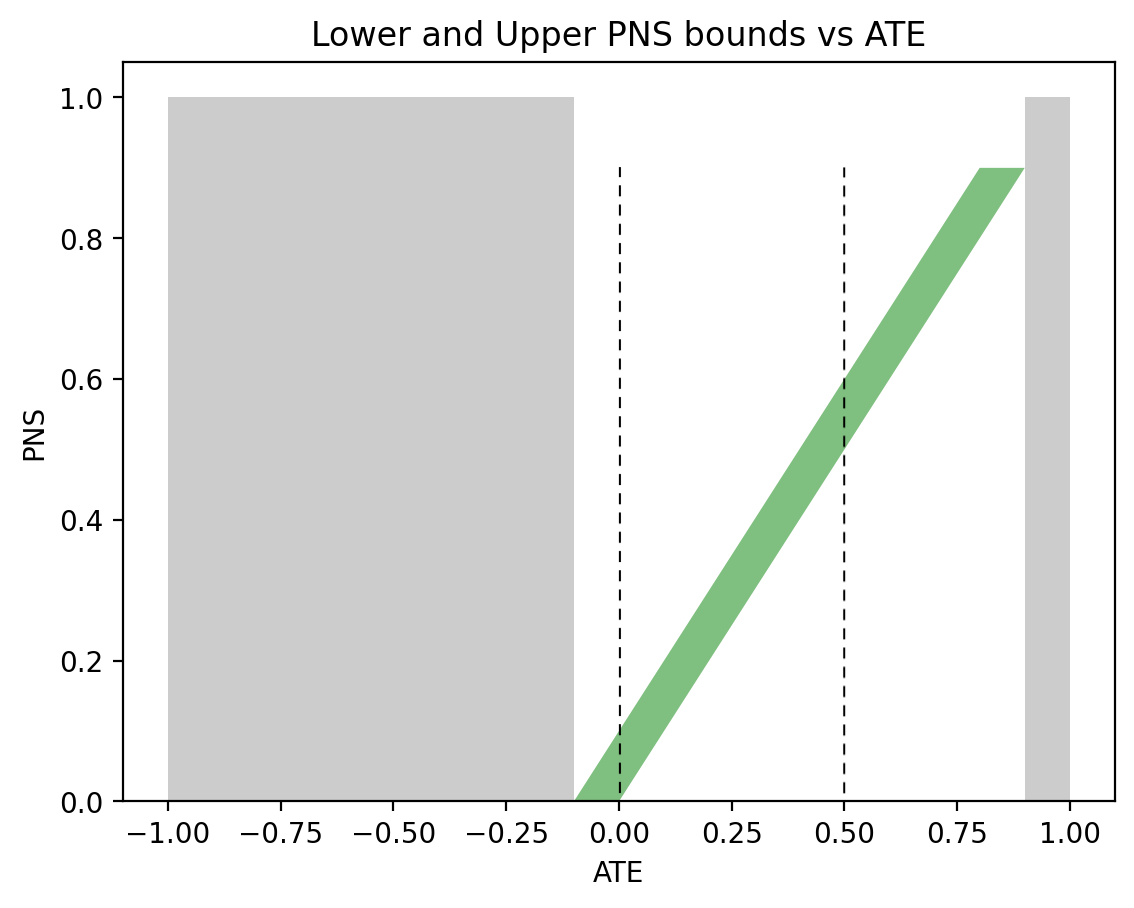
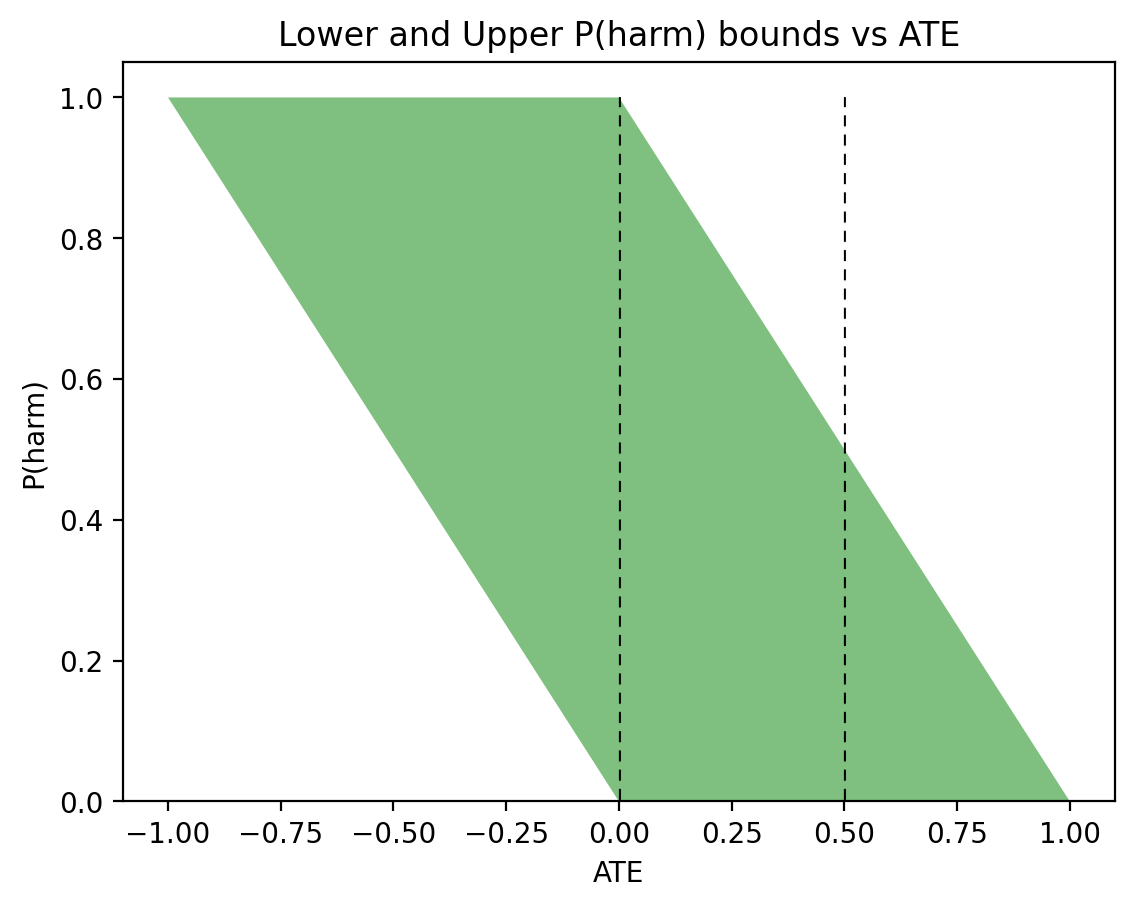
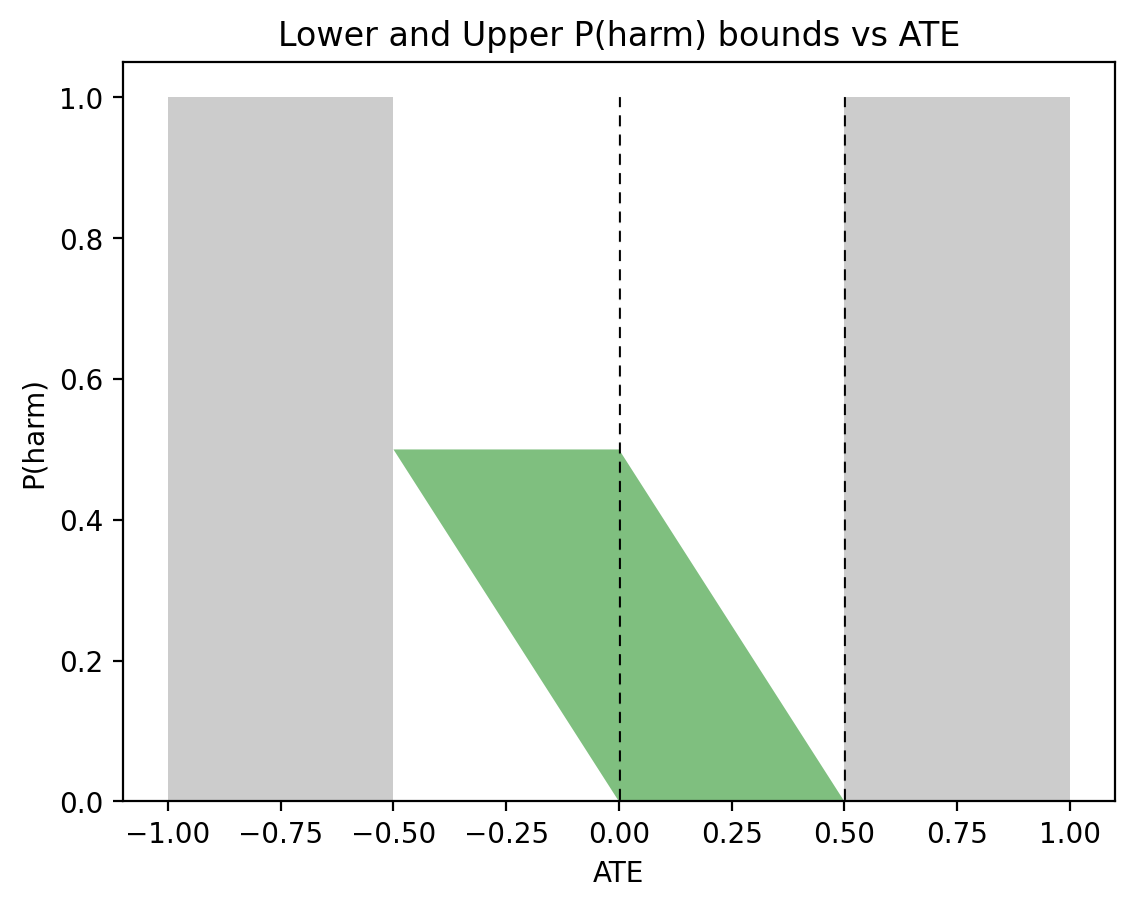
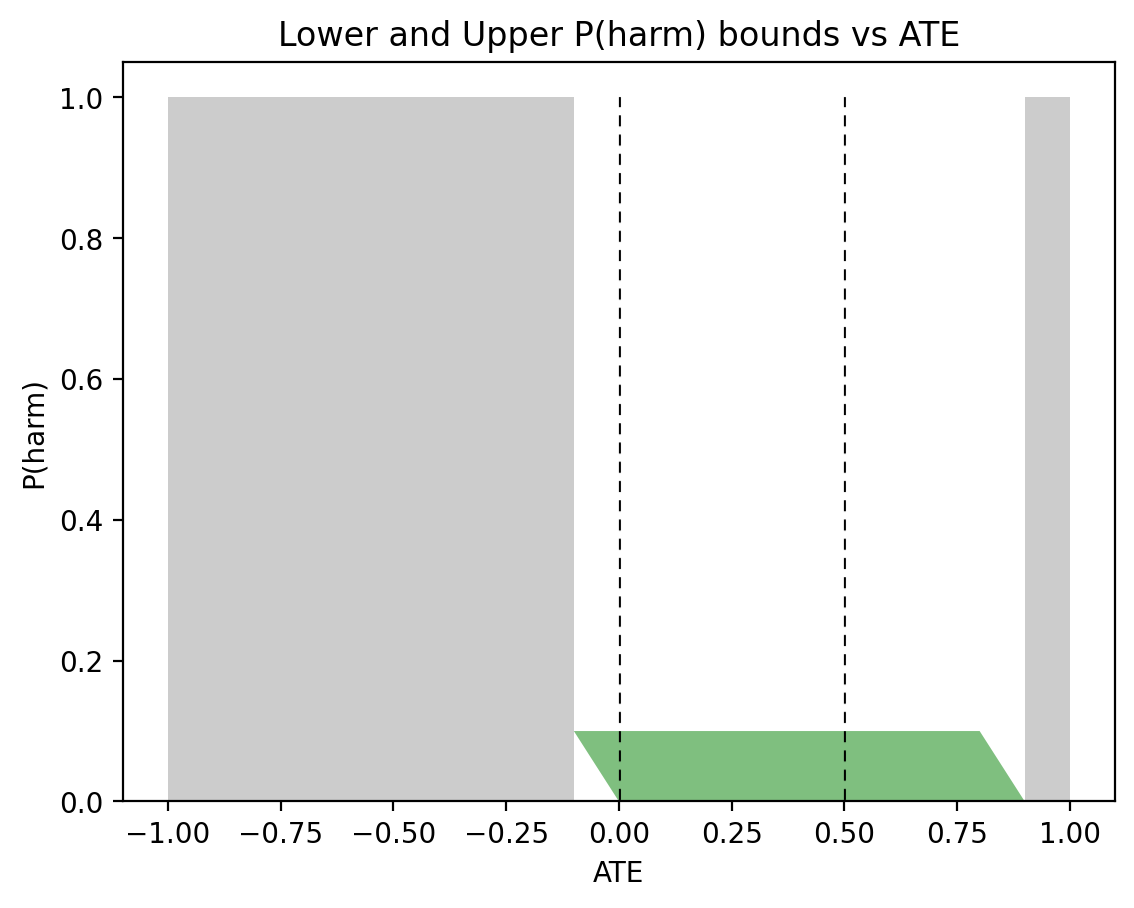
{kind=link}