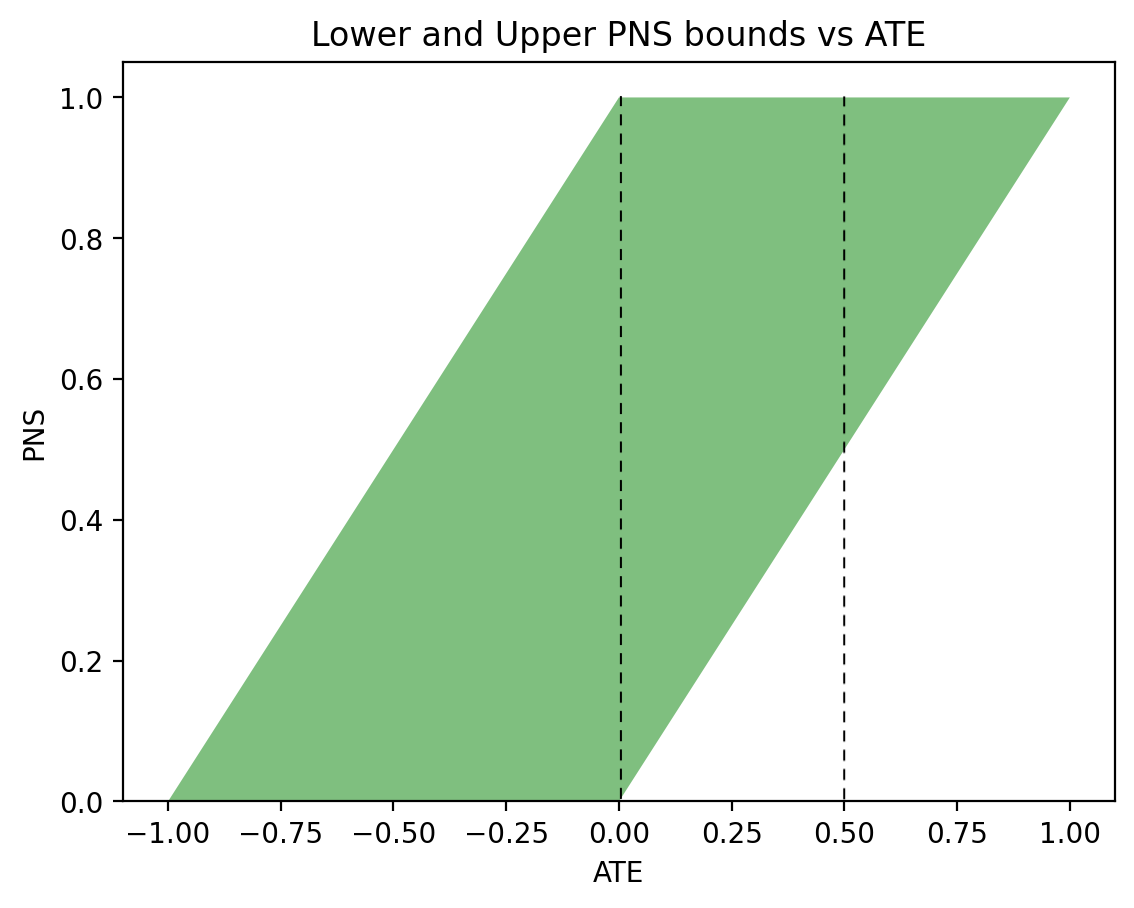
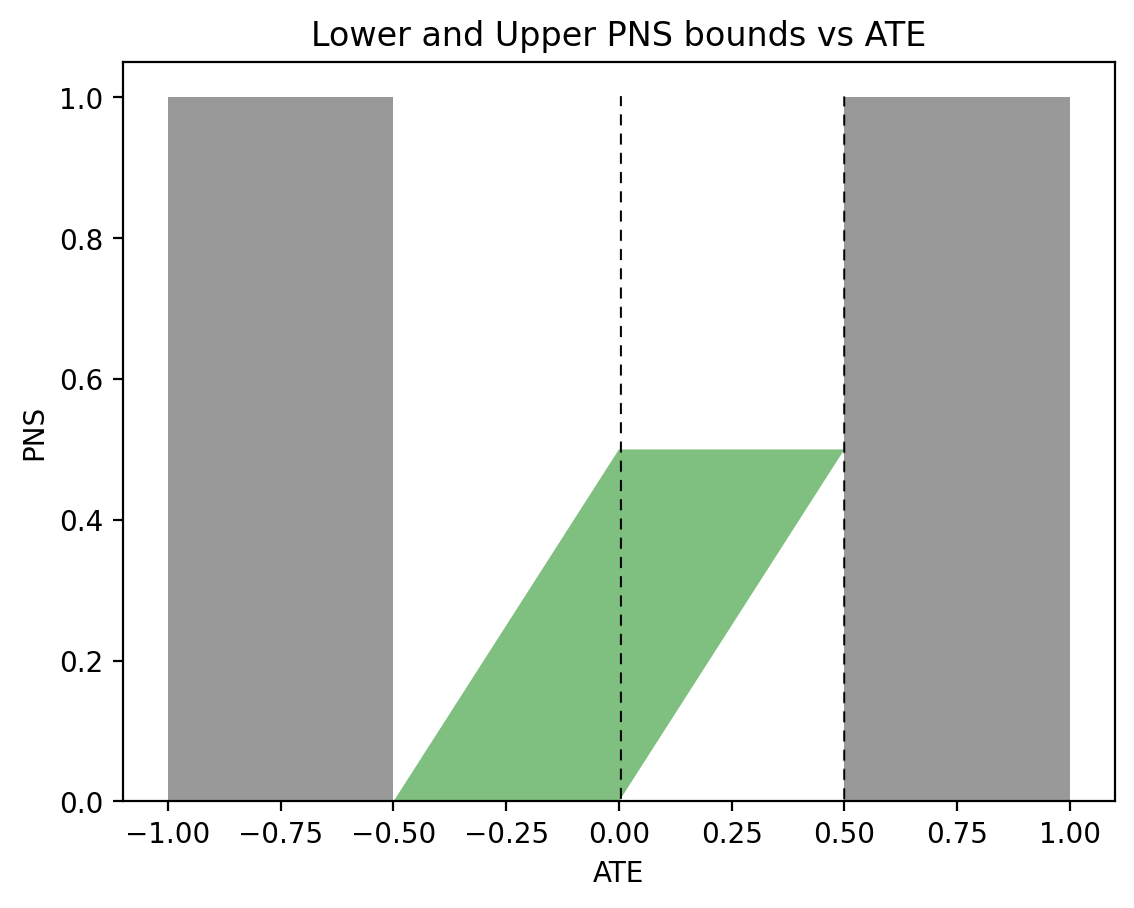
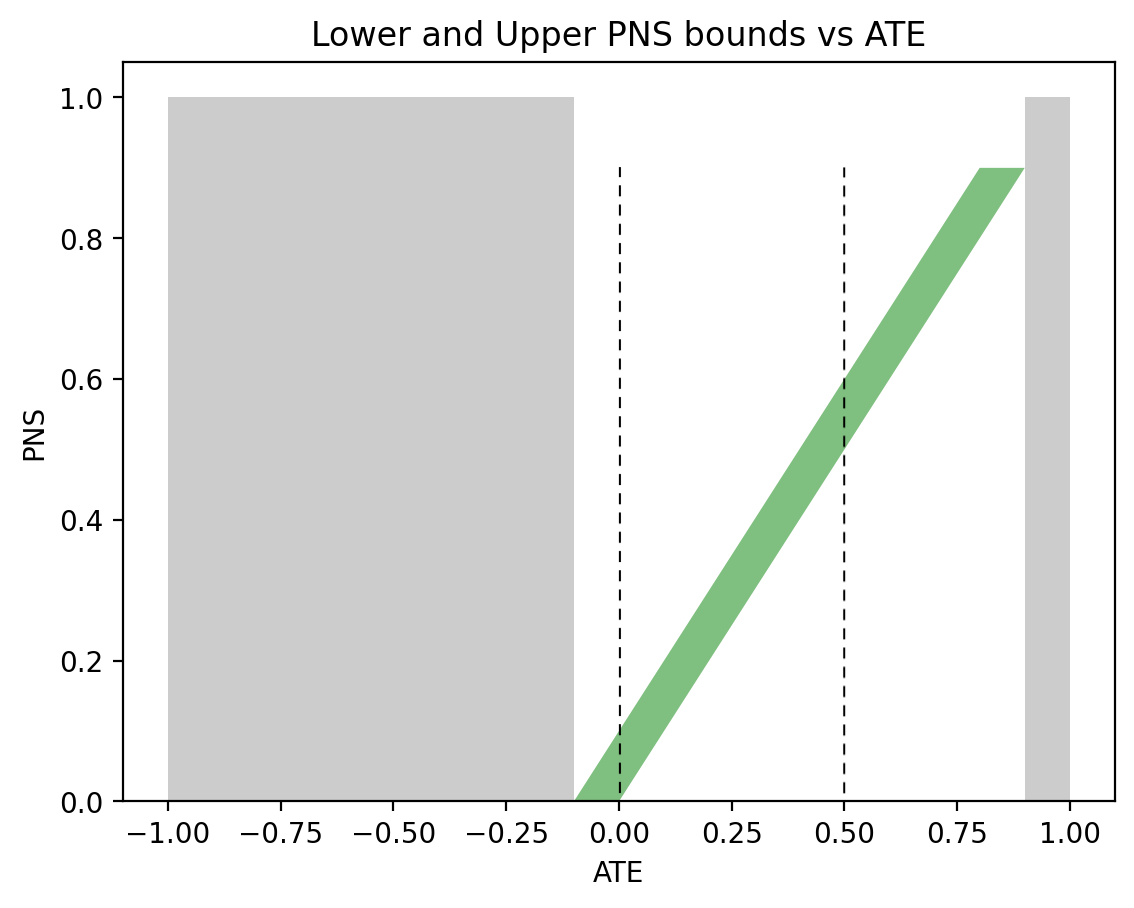
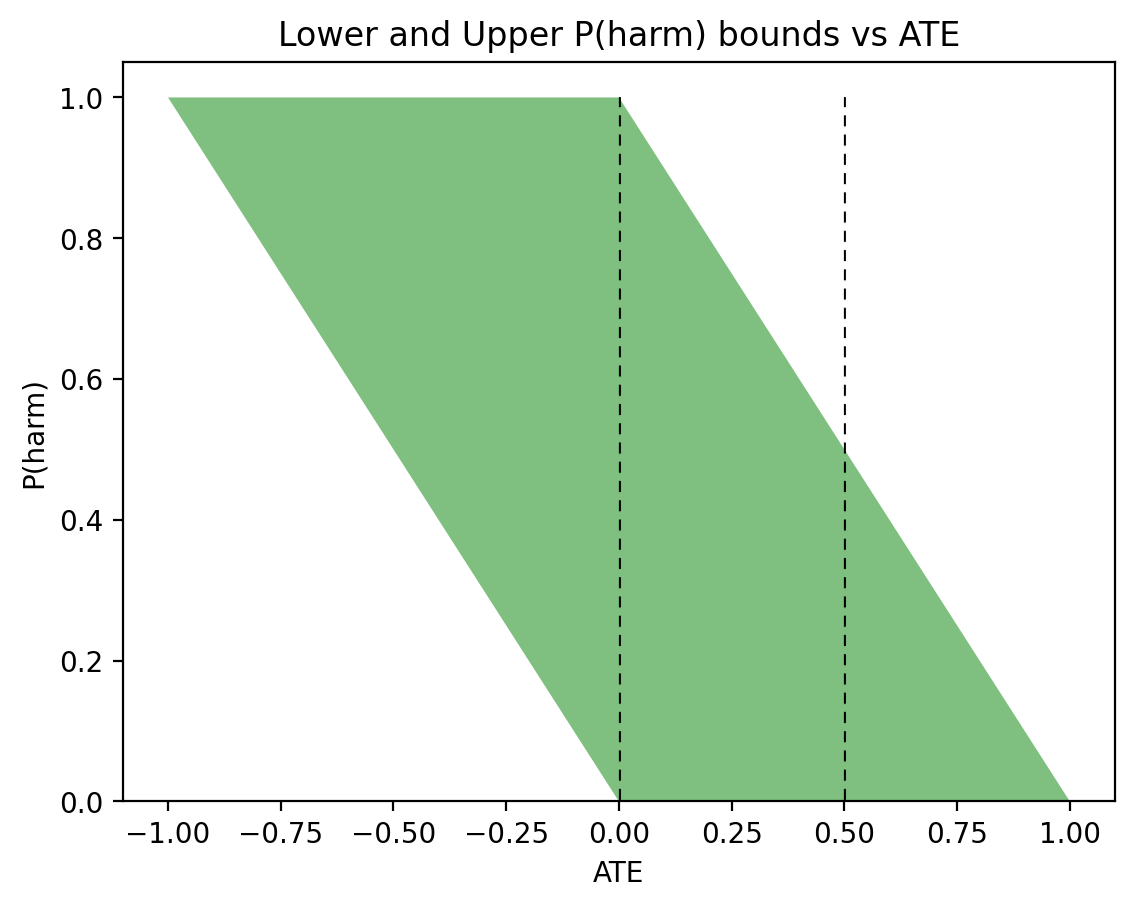
In the past two days I have been engaged in discussions regarding Andrew Gelman’s review of Book of Why.
These discussions unveils some of our differences as well as some agreements. I am posting some of the discussions below, because Gelman’s blog represents the thinking of a huge segment of practicing statisticians who are, by and large, not very talkative about causation. It is interesting therefore to understand how they think, and what makes them tick.
Judea Pearl says: January 12, 2019 at 8:24 am
Andrew,
I appreciate your kind invitation to comment on your blog. Let me start with a Tweet that I posted on https://twitter.com/yudapearl
(updated 1.10.19)
1.8.19 @11:59pm – Gelman’s review of #Bookofwhy should be of interest because it represents an attitude that paralyzes wide circles of statistical researchers. My initial reaction is now posted on https://bit.ly/2H3BH3b Related posts: https://ucla.in/2sgzkPZ and https://ucla.in/2v72QK5
These postings speak for themselves but I would like to respond here to your recommendation: “Similarly, I’d recommend that Pearl recognize that the apparatus of statistics, hierarchical regression modeling, interactions, post-stratification, machine learning, etc etc solves real problems in causal inference.”
It sounds like a mild and friendly recommendation, and your readers would probably get upset at anyone who would be so stubborn as to refuse it.
But I must. Because, from everything I know about causation, the apparatus you mentioned does NOT, and CANNOT solve any problem known as “causal” by the causal-inference community (which includes your favorites Rubin, Angrist, Imbens, Rosenbaum, etc etc.). Why?
Because the solution to any causal problem must rest on causal assumptions and the apparatus you mentioned has no representation for such assumptions.
1. Hierarchical models are based on set-subset relationships, not causal relationships.
2. “interactions” is not an apparatus unless you represent them in some model, and act upon them.
3. “post-stratification” is valid only after you decide what you stratify on, and this requires a causal structure (which you claim above to be an unnecessary “wrapping” and complication”)
4. “Machine learning” is just fancy curve fitting of data see https://ucla.in/2umzd65
Thus, what you call “statistical apparatus” is helpless in solving causal problems. We came to this juncture several times in the past and, invariably, you pointed me to books, articles, and elaborated works which, in your opinion, do solve “real life causal problems”. So, how are we going to resolve our disagreement on whether those “real life” problems are “causal” and, if they are, whether your solution of them is valid. I suggested applying your methods to toy problems whose causal character is beyond dispute. You did not like this solution, and I do not blame you, because solving ONE toy problem will turn your perception of causal analysis upside down. It is frightening. So I would not press you. But I will add another Tweet before I depart:
1.9.19 @2:55pm – An ounce of advice to readers who comment on this “debate”: Solving one toy problem in causal inference tells us more about statistics and science than ten debates, no matter who the debaters are. #Bookofwhy
Addendum. Solving ONE toy problem will tells you more than dozen books and articles and multi-cited reports. You can find many such toy problems (solved in R) here: https://ucla.in/2KYYviP sample of solution manual: https://ucla.in/2G11xUE
For your readers convenience, I have provided free access to chapter 4 here: https://ucla.in/2G2rWBv It is about counterfactuals and, if I were not inhibited by modesty, I would confess that it is the best text on counterfactuals and their applications that you can find anywhere.
I hope you take advantage of my honesty.
Enjoy
Judea
Andrew says: January 12, 2019 at 11:37 am
Judea:
We are in agreement. I agree that data analysis alone cannot solve any causal problems. Substantive assumptions are necessary too. To take a familiar sort of example, there are people out there who just think that if you fit a regression of the form, y = a + bx + cz + error, that the coefficients b and c can be considered as causal effects. At the level of data analysis, there are lots of ways of fitting this regression model. In some settings with good data, least squares is just fine. In more noisy problems, you can do better with regularization. If there is bias in the measurements of x, z, and y, that can be incorporated into the model also. But none of this legitimately gives us a causal interpretation until we make some assumptions. There are various ways of expressing such assumptions, and these are talked about in various ways in your books, in the books by Angrist and Pischke, in the book by Imbens and Rubin, in my book with Hill, and in many places. Your view is that your way of expressing causal assumptions is better than the expositions of Angrist and Pischke, Imbens and Rubin, etc., that are more standard in statistics and econometrics. You may be right! Indeed, I think that for some readers your formulation of this material is the best thing out there.
Anyway, just to say it again: We agree on the fundamental point. This is what I call in the above post the division of labor, quoting Frank Sinatra etc. To do causal inference requires (a) assumptions about causal structure, and (b) models of data and measurement. Neither is enough. And, as I wrote above:
I agree with Pearl and Mackenzie that typical presentations of statistics, econometrics, etc., can focus way too strongly on the quantitative without thinking at all seriously about the qualitative aspects of the problem. It’s usually all about how to get the answer given the assumptions, and not enough about where the assumptions come from. And even when statisticians write about assumptions, they tend to focus on the most technical and least important ones, for example in regression focusing on the relatively unimportant distribution of the error term rather than the much more important concerns of validity and additivity.
If all you do is set up probability models, without thinking seriously about their connections to reality, then you’ll be missing a lot, and indeed you can make major errors in casual reasoning . . .
Where we disagree is just on terminology, I think. I wrote, “the apparatus of statistics, hierarchical regression modeling, interactions, poststratification, machine learning, etc etc., solves real problems in causal inference.” When I speak of this apparatus, I’m not just talking about probability models; I’m also talking about assumptions that map those probability models to causality. I’m talking about assumptions such as those discussed by Angrist and Pischke, Imbens and Rubin, etc.—and, quite possibly, mathematically equivalent in these examples to assumptions expressed by you.
So, to summarize: To do causal inference, we need (a) causal assumptions (assumptions of causal structure), and (b) models or data analysis. The statistics curriculum spends much more time on (b) than (a). Econometrics focuses on (a) as well as (b). You focus on (a). When Angrist, Pischke, Imbens, Rubin, Hill, me, and various others do causal inference, we do both (a) and (b). You argue that if we were to follow your approach on (a), we’d be doing better work for those problems that involve causal inference. You may be right, and in any case I’m glad you and Mackenzie wrote this book which so many people have found helpful, just as I’m glad that the aforementioned researchers wrote their books on causal inference which so many have found helpful. A framework for causal inference—whatever that framework may be—is complementary to, not in competition with, data-analysis tools such as hierarchical modeling, poststratification, machine learning, etc.
P.S. I’ll ignore the bit in your comment where you say you know what is “frightening” to me.
Judea Pearl says: January 13, 2019 at 6:59 am
Andrew,
I would love to believe that where we disagree is just on terminology. Indeed, I see sparks of convergence in your last post, where you enlighten me to understand that by “the apparatus of statistics, …’ you include the assumptions that PO folks (Angrist and Pischke, Imbens and Rubin etc.) are making, namely, assumptions of conditional ignorability. This is a great relief, because I could not see how the apparatus of regression, interaction, post-stratification or machine learning alone, could elevate you from rung-1 to rung-2 of the Ladder of Causation. Accordingly, I will assume that whenever Gelman and Hill talk about causal inference they tacitly or explicitly make the ignorability assumptions that are needed to take them
from associations to causal conclusions. Nice. Now we can proceed to your summary and see if we still have differences beyond terminology.
I almost agree with your first two sentences: “So, to summarize: To do causal inference, we need (a) causal assumptions (assumptions of causal structure), and (b) models or data analysis. The statistics curriculum spends much more time on (b) than (a)”.
But we need to agree that just making “causal assumptions” and leaving them hanging in the air is not enough. We need to do something with the assumptions, listen to them, and process them so as to properly guide us in the data analysis stage.
I believe that by (a) and (b) you meant to distinguish identification from estimation. Identification indeed takes the assumptions and translate them into a recipe with which we can operate on the data so as to produce a valid estimate of the research question of interest. If my interpretation of your (a) and (b) distinction is correct, permit me to split (a) into (a1) and (a2) where (a2) stands for identification.
With this refined-taxonomy, I have strong reservation to your third sentence: “Econometrics focuses on (a) as well as (b).” Not all of econometrics. The economists you mentioned, while commencing causal analysis with “assumptions” (a1), vehemently resist to organizing these assumptions in any “structure”, be it a DAG or structural equations (Some even pride themselves of being “model-free”). Instead, they restrict their assumptions to conditional ignorability statements so as to justify familiar estimation routines. [In https://ucla.in/2mhxKdO, I labeled them: “experimentalists” or “structure-free economists” to be distinguished from “structuralists” like Heckman, Sims, or Matzkin.]
It is hard to agree therefore that these “experimentalists” focus on (a2) — identification. They actually assume (a2) away rather than use it to guide data analysis.
Continuing with your summary, I read: “You focus on (a).” Agree. I interpret (a) to mean (a) = (a1) + (a2) and I let (b) be handled by smart statisticians, once they listen to the guidance of (a2).
Continuing, I read:
“When Angrist, Pischke, Imbens, Rubin, Hill, me, and various others do causal inference, we do both (a) and (b). Not really. And it is not a matter of choosing “an approach”. By resisting structure, these researchers a priori deprive themselves of answering causal questions that are identifiable by do-calculus and not by a single conditional ignorability assumption. Each of those questions may require a different estimand, which means that you cannot start doing the “data analysis” phase before completing the identification phase.
[Currently, even questions that are identifiable by conditional ignorability assumption cannot be answered by structure-free PO folks, because deciding on the conditioning set of covariates is intractable without the aid of DAGs, but this is a matter of efficiency not of essence.]
But your last sentence is hopeful:
“A framework for causal inference — whatever that that framework may be — is complementary to, not in competition with, data-analysis tools such as hierarchical modeling, post-stratification, machine learning, etc.”
Totally agree, with one caveat: the framework has to be a genuine “framework,” ie, capable of leverage identification to guide data-analysis.
Let us look now at why a toy problem would be frightening; not only to you, but to anyone who believes that the PO folks are offering a viable framework for causal inference.
Lets take the simplest causal problem possible, say a Markov chain X —>Z—>Y with X standing for Education, Z for Skill and Y for Salary. Let Salary be determined by Skill only, regardless of Education. Our research problem is to find the causal effect of Education on Salary given observational data of (perfectly measured) X,Y,Z.
To appreciate the transformative power of a toy example, please try to write down how Angrist, Pischke, Imbens, Rubin, Hill, would go about doing (a) and (b) according to your understanding of their framework. You are busy, I know, so let me ask any of your readers to try and write down step by step how the graph-less school would go about it. Any reader who tries this exercise ONCE will never be thesame. It is hard to believe unless you actually go through this frightening exercise, please try.
Repeating my sage-like advice: Solving one toy problem in causal inference tells us more about statistics and science than ten debates, no matter who the debaters are.
Try it.
[Judea Pearl added in editing: I have received no solution thus far, not even an attempt. For readers of this blog, the chain is part of the front-door model which is treated in Causality pp. 232-4, in both graphical and potential outcome frameworks. I have yet to meet a PO researcher who can formulate this toy story in PO, let alone solve it. Not because they can’t, but because the very idea of listening to their understanding of a problem and translating that understanding to formal assumption is foreign to them, having been conditioned to assume ignorability and estimate a quantity that is easily estimable]
Andrew says:January 13, 2019 at 8:26 pm
Judea:
I think we agree on much of the substance. And I agree with you regarding “not all econometrics” (and, for that matter, not all of statistics, not all of sociology, etc.). As I wrote in my review of your book with Mackenzie, and in my review of Angrist and Pischke’s book, causal identification is an important topic and worth its own books.
In practice, our disagreement is, I think, that we focus on different sorts of problems and different sorts of methods. And that’s fine! Division of labor. You have toy problems that interest you, I have toy problems that interest me. You have applied problems that interest you, I have applied problems that interest me. I would not expect you to come up with methods of solving the causal inference problems that I work on, but that’s OK: your work is inspirational to many people and I can well believe it has been useful in certain applications as well as in developing conceptual understanding. I consider toy problems of my own for that same reason. I’m not particularly interested in your toy problems, but that’s fine; I doubt you’re particularly interested in the problems I focus on. It’s a big world out there.
In the meantime, you continue to characterize me as being frightened or lacking courage. I wish you’d stop doing that.
[Judea Pearl added in editing: Gelman wants to move identification to separate books, because it is important, but the fact that one cannot start estimation before having an identifiable estimand is missing from his comment. Is he aware of it? Does he really do estimation before identification? I do not know, it is a foreign culture to me.]
Judea Pearl says: January 13, 2019 at 10:51 pm
Andrew,
Convergence is in sight, modulo two corrections:
1. You say:
“You [Pearl] have toy problems that interest you, I [Andrew] have toy problems that interest me. …I doubt you’re particularly interested in the problems I focus on. ”
Wrong! I am very interested in your toy problems, especially those with causal flavor. Why? Because I love to challenge the SCM framework with new tasks and new angles that other researchers found to be important, and see if SCM can be enriched with expanded scope. So, by all means, if you have a new twist, shoot. I have not been able to do it in the past, because your shots were not toy-like, e.g., 3-4 variables, clear task, with correct answer known.
2. You say:
“you continue to characterize me as being frightened or lacking courage” This was not my intention. My last remark on frightening toys was general, everyone is frightened by the honesty and transparency of toys — the adequacy of one’s favorite method is undergoing a test of fire. Who wouldn’t be frightened? But, since you prefer, I will stop using this metaphor.
3. Starting afresh, and the sake of good spirit: How about attacking a toy problem? Just for fun, just for sport.
Andrew says: January 13, 2019 at 11:24 pm
Judea:
I’ve attacked a lot of toy problems.
For an example of a toy problem in causality, see pages 962-963 of this article.
But most of the toy problems I’ve looked at do not involve causality; see for example this paper, item 4 in this post, and this paper. This article on experimental design is simple enough that I think it could count as a toy problem: it’s a simple example without data which allows us to compare different methods. And here’s a theoretical paper I wrote awhile ago that has three toy examples. Not involving causal inference, though.
I’ve written lots of papers with causal inference, but they’re almost all applied work. This may be because I consider myself much more of a practitioner of causal inference than a researcher on causal inference. To the extent I’ve done research on causal inference, it’s mostly been to resolve some confusions in my mind (as in this paper).
This gets back to the division-of-labor thing. I’m happy for you and Imbens and Hill and Robins and VanderWeele and others to do research on fundamental methods for causal inference, while I do research on statistical analysis. The methods that I’ve learned have allowed my colleagues and I to make progress on a lot of applied problems in causal inference, and have given me some clarity in understanding problems with some naive formulations of causal reasoning (as in the first reference above in this comment).
[Judea Pearl. Added in editing: Can one really make progress on a lot of applied problems in causal inference without dealing with identification Evidently, PO folks think so, at least those in Gelman’s circles]
As I wrote in my above post, I think your book with Mackenzie has lots of great things in it; I just can’t go with a statement such as, “Using a calculus of cause and effect developed by Pearl and others, scientists now have the ability to answer such questions as whether a drug cured an illness, when discrimination is to blame for disparate outcomes, and how much worse global warming can make a heat wave”—because scientists have been answering such questions before Pearl came along, and scientists continue to answer such questions using methods other than Pearl’s. For what it’s worth, I don’t think the methods that my colleagues and I have developed are necessary for solving these or any problems. Our methods are helpful in some problems, some of the time, at least until something better comes along—I think that’s pretty much all that any of us can hope for! That, and we can hope that our writings inspire new researchers to come up with new methods that are useful in the future.
Judea Pearl says:January 14, 2019 at 2:18 am
Andrew,
Agree to division of labor: causal inference on one side and statistical analysis on the other.
Assuming that you give me some credibility on the first, let me try and show you that even the publisher advertisement that you mock with disdain is actually true and carefully expressed. It reads: “Using a calculus of cause and effect developed by Pearl and others, scientists now have the ability to answer such questions as whether a drug cured an illness, when discrimination is to blame for disparate outcomes, and how much worse global warming can make a heat wave”.
First, note that it includes “Pearl and others”, which theoretically might include the people you have in mind. But it does not; it refers to those who developed mathematical formulation and mathematical tools to answer such questions. So let us examine the first question: “whether a a drug cured an illness”. This is a counterfactual “cause of effect” type question. Do you know when it was first formulated mathematically? [Don Rubin declared it non-scientific].
Now lets go to the second: “when discrimination is to blame for disparate outcomes,” This is a mediation problem. Care to guess when this problem was first formulated (see Book of Why chapter 9) and what the solution is Bottom line, Pearl is not as thoughtless as your review portrays him to be and, if you advise your readers to control their initial reaction: “Hey, statisticians have been doing it for centuries” they would value learning how things were first formulated, first solved and why statisticians were not always the first.
Andrew says:January 14, 2019 at 6:46 pm
Judea:
I disagree with your implicit claim that, before your methods were developed, scientists were not able to answer such questions as whether a drug cured an illness, when discrimination is to blame for disparate outcomes, and how much worse global warming can make a heat wave. I doubt much will be gained by discussing this particular point further so I’m just clarifying that this is a point of disagreement.
Also, I don’t think in my review I portrayed you as thoughtless. My message was that your book with Mackenzie is valuable and interesting even though it has some mistakes. In my review I wrote about the positive part as well as the mistakes. Your book is full of thought!
[Judea Pearl. Added in edit: Why can’t Gelman “go with a statement such as, “Using a calculus of cause and effect developed by Pearl and others, scientists now have the ability to answer such questions as whether a drug cured an illness, when discrimination is to blame for disparate outcomes, and how much worse global warming can make a heat wave”? His answer is: “because scientists have been answering such questions before Pearl came along” True, by trial and error, but not by mathematical analysis. And my statement marvels at the ability of doing it analytically. So why can’t Gelman acknowledge that a marvelous progress has been made, not by me, but by several researchers who realized that graph-less PO is a deadend.?]