What Statisticians Want to Know about Causal Inference and The Book of Why
I was privileged to be interviewed recently by David Hand, Professor of Statistics at Imperial College, London, and a former President of the Royal Statistical Society. I would like to share this interview with readers of this blog since many of the questions raised by David keep coming up in my conversations with statisticians and machine learning researchers, both privately and on Twitter.
For me, David represents mainstream statistics and, the reason I find his perspective so valuable is that he does not have a stake in causality and its various formulations. Like most mainstream statisticians, he is simply curious to understand what the big fuss is all about and how to communicate differences among various approaches without taking sides.
So, I’ll let David start, and I hope you find it useful.
Judea Pearl Interview by David Hand
There are some areas of statistics which seem to attract controversy and disagreement, and causal modelling is certainly one of them. In an attempt to understand what all the fuss is about, I asked Judea Pearl about these differences in perspective. Pearl is a world leader in the scientific understanding of causality. He is a recipient of the AMC Turing Award (computing’s “Nobel Prize”), for “fundamental contributions to artificial intelligence through the development of a calculus for probabilistic and causal reasoning”, the David E. Rumelhart Prize for Contributions to the Theoretical Foundations of Human Cognition, and is a Fellow of the American Statistical Association.
QUESTION 1:
I am aware that causal modelling is a hotly contested topic, and that there are alternatives to your perspective – the work of statisticians Don Rubin and Phil Dawid spring to mind, for example. Words like counterfactual, Popperian falsifiability, potential outcomes, appear. I’d like to understand the key differences between the various perspectives, so can you tell me what are the main grounds on which they disagree?
ANSWER 1:
You might be surprised to hear that, despite what seems to be hotly contested debates, there are very few philosophical differences among the various “approaches.” And I put “approaches” in quotes because the differences are more among historical traditions, or “frameworks” than among scientific principles. If we compare, for example, Rubin’s potential outcome with my framework, named “Structural Causal Models” (SCM), we find that the two are logically equivalent; a theorem in one is a theorem in the other and an assumption in one can be written as an assumption in the other. This means that, starting with the same set of assumptions, every solution obtained in one can also be obtained in the other.
But logical equivalence does not means “modeling equivalence” when we consider issues such as transparency, credibility or tractability. The equations for straight lines in polar coordinates are equivalent to those in Cartesian coordinates yet are hardly manageable when it comes to calculating areas of squares or triangles.
In SCM, assumptions are articulated in the form of equations among measured variables, each asserting how one variable responds to changes in another. Graphical models are simple abstractions of those equations and, remarkably, are sufficient for answering many causal questions when applied to non-experimental data. An arrow X—>Y in a graphical model represents the capacity to respond to such changes. All causal relationships are derived mechanically from those qualitative primitives, demanding no further judgment of the modeller.
In Rubin’s framework, assumptions are expressed as conditional independencies among counterfactual variables, also known as “ignorability conditions.” The mental task of ascertaining the plausibility of such assumptions is beyond anyone’s capacity, which makes it extremely hard for researchers to articulate or to verify. For example, the task of deciding which measurements to include in the analysis (or in the propensity score) is intractable in the language of conditional ignorability. Judging whether the assumptions are compatible with the available data, is another task that is trivial in graphical models and insurmountable in the potential outcome framework.
Conceptually, the differences can be summarized thus: The graphical approach goes where scientific knowledge resides, while Rubin’s approach goes where statistical routines need to be justified. The difference shines through when simple problems are solved side by side in both approaches, as in my book Causality (2009). The main reason differences between approaches are still debated in the literature is that most statisticians are watching these debates as outsiders, instead of trying out simple examples from beginning to end. Take for example Simpson’s paradox, a puzzle that has intrigued a century of statisticians and philosophers. It is still as vexing to most statisticians today as it was to Pearson in 1889, and the task of deciding which data to consult, the aggregated or the disaggregated is still avoided by all statistics textbooks.
To summarize, causal modeling, a topic that should be of prime interest to all statisticians, is still perceived to be a “hotly contested topic”, rather than the main frontier of statistical research. The emphasis on “differences between the various perspectives” prevents statisticians from seeing the exciting new capabilities that now avail themselves, and which “enable us to answer questions that we have always wanted but were afraid to ask.” It is hard to tell whether fears of those “differences” prevent statisticians from seeing the excitement, or the other way around, and cultural inhibitions prevent statisticians from appreciating the excitement, and drive them to discuss “differences” instead.
QUESTION 2:
There are different schools of statistics, but I think that most modern pragmatic applied statisticians are rather eclectic, and will choose a method which has the best capability to answer their particular questions. Does the same apply to approaches to causal modelling? That is, do the different perspectives have strengths and weaknesses, and should we be flexible in our choice of approach?
ANSWER 2:
These strengths and weaknesses are seen clearly in the SCM framework, which unifies several approaches and provides a flexible way of leveraging the merits of each. In particular, SCM combines graphical models and potential outcome logic. The graphs are used to encode what we know (i.e., the assumptions we are willing to defend) and the logic is used to encode what we wish to know, that is, the research question of interest. Simple mathematical tools can then combine these two with data and produce consistent estimates.
The availability of these unifying tools now calls on statisticians to become actively involved in causal analysis, rather than attempting to judge approaches from a distance. The choice of approach will become obvious once research questions are asked and the stage is set to articulate subject matter information that is necessary in answering those questions.
QUESTION 3:
To a very great extent the modern big data revolution has been driven by so-called “databased” models and algorithms, where understanding is not necessarily relevant or even helpful, and where there is often no underlying theory about how the variables are related. Rather, the aim is simply to use data to construct a model or algorithm which will predict an outcome from input variables (deep learning neural networks being an illustration). But this approach is intrinsically fragile, relying on an assumption that the data properly represent the population of interest. Causal modelling seems to me to be at the opposite end of the spectrum: it is intrinsically “theory-based”, because it has to begin with a causal model. In your approach, described in an accessible way in your recent book The Book of Why, such models are nicely summarised by your arrow charts. But don’t theory-based models have the complementary risk that they rely heavily on the accuracy of the model? As you say on page 160 of The Book of Why, “provided the model is correct”.
ANSWER 3:
When the tasks are purely predictive, model-based methods are indeed not immediately necessary and deep neural networks perform surprisingly well. This is level-1 (associational) in the Ladder of Causation described in The Book of Why. In tasks involving interventions, however (level-2 of the Ladder), model-based methods become a necessity. There is no way to predict the effect of policy interventions (or treatments) unless we are in possession of either causal assumptions or controlled randomized experiments employing identical interventions. In such tasks, and absent controlled experiments, reliance on the accuracy of the model is inevitable, and the best we can do is to make the model transparent, so that its accuracy can be (1) tested for compatibility with data and/or (2) judged by experts as well as policy makers and/or (3) subjected to sensitivity analysis.
A major reason why statisticians are reluctant to state and rely on untestable modeling assumptions stems from lack of training in managing such assumptions, however plausible. Even stating such unassailable assumptions as “symptoms do not cause diseases” or “drugs do not change patient’s sex” require a vocabulary that is not familiar to the great majority of living statisticians. Things become worse in the potential outcome framework where such assumptions resist intuitive interpretation, let alone judgment of plausibility. It is important at this point to go back and qualify my assertion that causal models are not necessary for purely predictive tasks. Many tasks that, at first glance appear to be predictive, turn out to require causal analysis. A simple example is the problem of external validity or inference across populations. Differences among populations are very similar to differences induced by interventions, hence methods of transporting information from one population to another can leverage all the tools developed for predicting effects of interventions. A similar transfer applies to missing data analysis, traditionally considered a statistical problem. Not so. It is inherently a causal problem since modeling the reason for missingness is crucial for deciding how we can recover from missing data. Indeed modern methods of missing data analysis, employing causal diagrams are able to recover statistical and causal relationships that purely statistical methods have failed to recover.
QUESTION 4:
In a related vein, the “backdoor” and “frontdoor” adjustments and criteria described in the book are very elegant ways of extracting causal information from arrow diagrams. They permit causal information to be obtained from observational data. Provided that is, the arrow diagram accurately represents the relationships between all the relevant variables. So doesn’t valid application of this elegant calculus depends critically on the accuracy of the base diagram?
ANSWER 4:
Of course. But as we have agreed above, EVERY exercise in causal inference “depends critically on the accuracy” of the theoretical assumptions we make. Our choice is whether to make these assumptions transparent, namely, in a form that allows us to scrutinize their veracity, or bury those assumptions in cryptic notation that prevents scrutiny.
In a similar vein, I must modify your opening statement, which described the “backdoor” and “frontdoor” criteria as “elegant ways of extracting causal information from arrow diagrams.” A more accurate description would be “…extracting causal information from rudimentary scientific knowledge.” The diagrammatic description of these criteria enhances, rather than restricts their range of applicability. What these criteria in fact do is extract quantitative causal information from conceptual understanding of the world; arrow diagrams simply represent the extent to which one has or does not have such understanding. Avoiding graphs conceals what knowledge one has, as well as what doubts one entertains.
QUESTION 5:
You say, in The Book of Why (p5-6) that the development of statistics led it to focus “exclusively on how to summarise data, not on how to interpret it.” It’s certainly true that when the Royal Statistical Society was established it focused on “procuring, arranging, and publishing ‘Facts calculated to illustrate the Condition and Prospects of Society’,” and said that “the first and most essential rule of its conduct [will be] to exclude carefully all Opinions from its transactions and publications.” But that was in the 1830s, and things have moved on since then. Indeed, to take one example, clinical trials were developed in the first half of the Twentieth Century and have a history stretching back even further. The discipline might have been slow to get off the ground in tackling causal matters, but surely things have changed and a very great deal of modern statistics is directly concerned with causal matters – think of risk factors in epidemiology or manipulation in experiments, for example. So aren’t you being a little unfair to the modern discipline?
ANSWER 5:
Ronald Fisher’s manifesto, in which he pronounced that “the object of statistical methods is the reduction of data” was published in 1922, not in the 19th century (Fisher 1922). Data produced in clinical trials have been the only data that statisticians recognize as legitimate carriers of causal information, and our book devotes a whole chapter to this development. With the exception of this singularity, however, the bulk of mainstream statistics has been glaringly disinterested in causal matters. And I base this observation on three faithful indicators: statistics textbooks, curricula at major statistics departments, and published texts of Presidential Addresses in the past two decades. None of these sources can convince us that causality is central to statistics.
Take any book on the history of statistics, and check if it considers causal analysis to be of primary concern to the leading players in 20th century statistics. For example, Stigler’s The Seven Pillars of Statistical Wisdom (2016) barely makes a passing remark to two (hardly known) publications in causal analysis.
I am glad you mentioned epidemiologists’ analysis of risk factors as an example of modern interest in causal questions. Unfortunately, epidemiology is not representative of modern statistics. In fact epidemiology is the one field where causal diagrams have become a second language, contrary to mainstream statistics, where causal diagrams are still a taboo. (e.g., Efron and Hastie 2016; Gelman and Hill, 2007; Imbens and Rubin 2015; Witte and Witte, 2017).
When an academic colleague asks me “Aren’t you being a little unfair to our discipline, considering the work of so and so?”, my answer is “Must we speculate on what ‘so and so’ did? Can we discuss the causal question that YOU have addressed in class in the past year?” The conversation immediately turns realistic.
QUESTION 6:
Isn’t the notion of intervening through randomisation still the gold standard for establishing causality?
ANSWER 6:
It is. Although in practice, the hegemony of randomized trial is being contested by alternatives. Randomized trials suffer from incurable problems such as selection bias (recruited subject are rarely representative of the target population) and lack of transportability (results are not applicable when populations change). The new calculus of causation helps us overcome these problems, thus achieving greater over all credibility; after all, observational studies are conducted at the natural habitat of the target population.
QUESTION 7:
What would you say are the three most important ideas in your approach? And what, in particular, would you like readers of The Book of Why to take away from the book.
ANSWER 7:
The three most important ideas in the book are: (1) Causal analysis is easy, but requires causal assumptions (or experiments) and those assumptions require a new mathematical notation, and a new calculus. (2) The Ladder of Causation, consisting of (i) association (ii) interventions and (iii) counterfactuals, is the Rosetta Stone of causal analysis. To answer a question at layer (x) we must have assumptions at level (x) or higher. (3) Counterfactuals emerge organically from basic scientific knowledge and, when represented in graphs, yield transparency, testability and a powerful calculus of cause and effect. I must add a fourth take away: (4) To appreciate what modern causal analysis can do for you, solve one toy problem from beginning to end; it would tell you more about statistics and causality than dozens of scholarly articles laboring to overview statistics and causality.
REFERENCES
Efron, B. and Hastie, T., Computer Age Statistical Inference: Algorithms, Evidence, and Data Science, New York, NY: Cambridge University Press, 2016.
Fisher, R., “On the mathematical foundations of theoretical statistics,” Philosophical Transactions of the Royal Society of London, Series A 222, 311, 1922.
Gelman, A. and Hill, J., Data Analysis Using Regression and Multilevel/Hierarchical Models, New York: Cambridge University Press, 2007.
Imbens, G.W. and Rubin, D.B., Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction, Cambridge, MA: Cambridge University Press, 2015.
Witte, R.S. and Witte, J.S., Statistics, 11th edition, Hoboken, NJ: John Wiley & Sons, Inc. 2017.
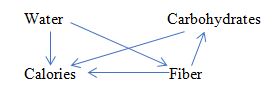



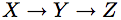 which represents the structural equations:
which represents the structural equations:
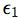 and
and 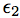 being omitted factors such that X,
being omitted factors such that X,