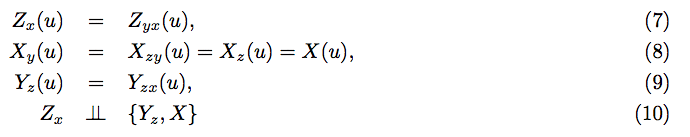On the First Law of Causal Inference
In several papers and lectures I have used the rhetorical title “The First Law of Causal Inference” when referring to the structural definition of counterfactuals:

The more I talk with colleagues and students, the more I am convinced that the equation deserves the title. In this post, I will explain why.
As many readers of Causality (Ch. 7) would recognize, Eq. (1) defines the potential-outcome, or counterfactual, Y_x(u) in terms of a structural equation model M and a submodel, M_x, in which the equations determining X is replaced by a constant X=x. Computationally, the definition is straightforward. It says that, if you want to compute the counterfactual Y_x(u), namely, to predict the value that Y would take, had X been x (in unit U=u), all you need to do is, first, mutilate the model, replace the equation for X with X=x and, second, solve for Y. What you get IS the counterfactual Y_x(u). Nothing could be simpler.
So, why is it so “fundamental”? Because from this definition we can also get probabilities on counterfactuals (once we assign probabilities, P(U=u), to the units), joint probabilities of counterfactuals and observables, conditional independencies over counterfactuals, graphical visualization of potential outcomes, and many more. [Including, of course, Rubin’s “science”, Pr(X,Y(0),(Y1))]. In short, we get everything that an astute causal analyst would ever wish to define or estimate, given that he/she is into solving serious problems in causal analysis, say policy analysis, or attribution, or mediation. Eq. (1) is “fundamental” because everything that can be said about counterfactuals can also be derived from this definition.
[See the following papers for illustration and operationalization of this definition:
http://ftp.cs.ucla.edu/pub/stat_ser/r431.pdf
http://ftp.cs.ucla.edu/pub/stat_ser/r391.pdf
http://ftp.cs.ucla.edu/pub/stat_ser/r370.pdf
also, Causality chapter 7.]
However, it recently occurred on me that the conceptual significance of this definition is not fully understood among causal analysts, not only among “potential outcome” enthusiasts, but also among structural equations researchers who practice causal analysis in the tradition of Sewall Wright, O.D. Duncan, and Trygve Haavelmo. Commenting on the flood of methods and results that emerge from this simple definition, some writers view it as a mathematical gimmick that, while worthy of attention, need to be guarded with suspicion. Others labeled it “an approach” that need be considered together with “other approaches” to causal reasoning, but not as a definition that justifies and unifies those other approaches.
Even authors who advocate a symbiotic approach to causal inference — graphical and counterfactuals — occasionally fail to realize that the definition above provides the logic for any such symbiosis, and that it constitutes in fact the semantical basis for the potential-outcome framework.
I will start by addressing the non-statisticians among us; i.e., economists, social scientists, psychometricians, epidemiologists, geneticists, metereologists, environmental scientists and more, namely, empirical scientists who have been trained to build models of reality to assist in analyzing data that reality generates. To these readers I want to assure that, in talking about model M, I am not talking about a newly invented mathematical object, but about your favorite and familiar model that has served as your faithful oracle and guiding light since college days, the one that has kept you cozy and comfortable whenever data misbehaved. Yes, I am talking about the equation

that you put down when your professor asked: How would household spending vary with income, or, how would earning increase with education, or how would cholesterol level change with diet, or how would the length of the spring vary with the weight that loads it. In short, I am talking about innocent equations that describe what we assume about the world. They now call them “structural equations” or SEM in order not to confuse them with regression equations, but that does not make them more of a mystery than apple pie or pickled herring. Admittedly, they are a bit mysterious to statisticians, because statistics textbooks rarely acknowledge their existence [Historians of statistics, take notes!] but, otherwise, they are the most common way of expressing our perception of how nature operates: A society of equations, each describing what nature listens to before determining the value it assigns to each variable in the domain.
Why am I elaborating on this perception of nature? To allay any fears that what is put into M is some magical super-smart algorithm that computes counterfactuals to impress the novice, or to spitefully prove that potential outcomes need no SUTVA, nor manipulation, nor missing data imputation; M is none other but your favorite model of nature and, yet, please bear with me, this tiny model is capable of generating, on demand, all conceivable counterfactuals: Y(0),Y(1), Y_x, Y_{127}, X_z, Z(X(y)) etc. on and on. Moreover, every time you compute these potential outcomes using Eq. (1) they will obey the consistency rule, and their probabilities will obey the laws of probability calculus and the graphoid axioms. And, if your model justifies “ignorability” or “conditional ignorability,” these too will be respected in the generated counterfactuals. In other words, ignorability conditions need not be postulated as auxiliary constraints to justify the use of available statistical methods; no, they are derivable from your own understanding of how nature operates.
In short, it is a miracle.
Not really! It should be self evident. Couterfactuals must be built on the familiar if we wish to explain why people communicate with counterfactuals starting at age 4 (“Why is it broken?” “Lets pretend we can fly”). The same applies to science; scientists have communicated with counterfactuals for hundreds of years, even though the notation and mathematical machinery needed for handling counterfactuals were made available to them only in the 20th century. This means that the conceptual basis for a logic of counterfactuals resides already within the scientific view of the world, and need not be crafted from scratch; it need not divorce itself from the scientific view of the world. It surely should not divorce itself from scientific knowledge, which is the source of all valid assumptions, or from the format in which scientific knowledge is stored, namely, SEM.
Here I am referring to people who claim that potential outcomes are not explicitly represented in SEM, and explicitness is important. First, this is not entirely true. I can see (Y(0), Y(1)) in the SEM graph as explicitly as I see whether ignorability holds there or not. [See, for example, Fig. 11.7, page 343 in Causality]. Second, once we accept SEM as the origin of potential outcomes, as defined by Eq. (1), counterfactual expressions can enter our mathematics proudly and explicitly, with all the inferential machinery that the First Law dictates. Third, consider by analogy the teaching of calculus. It is feasible to teach calculus as a stand-alone symbolic discipline without ever mentioning the fact that y'(x) is the slope of the function y=f(x) at point x. It is feasible, but not desirable, because it is helpful to remember that f(x) comes first, and all other symbols of calculus, e.g., f'(x), f”(x), [f(x)/x]’, etc. are derivable from one object, f(x). Likewise, all the rules of differentiation are derived from interpreting y'(x) as the slope of y=f(x).
Where am I heading?
First, I would have liked to convince potential outcome enthusiasts that they are doing harm to their students by banning structural equations from their discourse, thus denying them awareness of the scientific basis of potential outcomes. But this attempted persuasion has been going on for the past two decades and, judging by the recent exchange with Guido Imbens (link), we are not closer to an understanding than we were in 1995. Even an explicit demonstration of how a toy problem would be solved in the two languages (link) did not yield any result.
Second, I would like to call the attention of SEM practitioners, including of course econometricians, quantitative psychologists and political scientists, and explain the significance of Eq. (1) in their fields. To them, I wish to say: If you are familiar with SEM, then you have all the mathematical machinery necessary to join the ranks of modern causal analysis; your SEM equations (hopefully in nonparametric form) are the engine for generating and understanding counterfactuals.; True, your teachers did not alert you to this capability; it is not their fault, they did not know of it either. But you can now take advantage of what the First Law of causal inference tells you. You are sitting on a gold mine, use it.
Finally, I would like to reach out to authors of traditional textbooks who wish to introduce a chapter or two on modern methods of causal analysis. I have seen several books that devote 10 chapters on SEM framework: identification, structural parameters, confounding, instrumental variables, selection models, exogeneity, model misspecification, etc., and then add a chapter to introduce potential outcomes and cause-effect analyses as useful new comers, yet alien to the rest of the book. This leaves students to wonder whether the first 10 chapters were worth the labor. Eq. (1) tells us that modern tools of causal analysis are not new comers, but follow organically from the SEM framework. Consequently, one can leverage the study of SEM to make causal analysis more palatable and meaningful.
Please note that I have not mentioned graphs in this discussion; the reason is simple, graphical modeling constitutes The Second Law of Causal Inference.
Enjoy both,
Judea
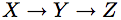 which represents the structural equations:
which represents the structural equations:
 and
and  being omitted factors such that X,
being omitted factors such that X,