Indirect Confounding and Causal Calculus (On three papers by Cox and Wermuth)
1. Introduction
This note concerns three papers by Cox and Wermuth (2008; 2014; 2015 (hereforth WC‘08, WC‘14 and CW‘15)) in which they call attention to a class of problems they named “indirect confounding,” where “a much stronger distortion may be introduced than by an unmeasured confounder alone or by a selection bias alone.” We will show that problems classified as “indirect confounding” can be resolved in just a few steps of derivation in do-calculus.
This in itself would not have led me to post a note on this blog, for we have witnessed many difficult problems resolved by formal causal analysis. However, in their three papers, Cox and Wermuth also raise questions regarding the capability and/or adequacy of the do-operator and do-calculus to accurately predict effects of interventions. Thus, a second purpose of this note is to reassure students and users of do-calculus that they can continue to apply these tools with confidence, comfort, and scientifically grounded guarantees.
Finally, I would like to invite the skeptic among my colleagues to re-examine their hesitations and accept causal calculus for what it is: A formal representation of interventions in real world situations, and a worthwhile tool to acquire, use and teach. Among those skeptics I must include colleagues from the potential-outcome camp, whose graph-evading theology is becoming increasing anachronistic (see discussions on this blog, for example, here).
2 Indirect Confounding – An Example
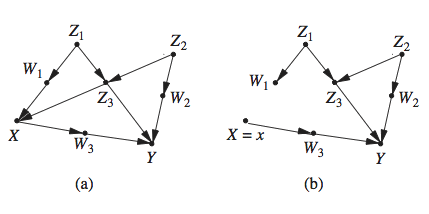
To illustrate indirect confounding, Fig. 1 below depicts the example used in WC‘08, which involves two treatments, one randomized (X), and the other (Z) taken in response to an observation (W) which depends on X. The task is to estimate the direct effect of X on the primary outcome (Y), discarding the effect transmitted through Z.
As we know from elementary theory of mediation (e.g., Causality, p. 127) we cannot block the effect transmitted through Z by simply conditioning on Z, for that would open the spurious path X → W ← U → Y , since W is a collider whose descendant (Z) is instantiated. Instead, we need to hold Z constant by external means, through the do-operator do(Z = z). Accordingly, the problem of estimating the direct effect of X on Y amounts to finding P(y|do(x, z)) since Z is the only other parent of Y (see Pearl (2009, p. 127, Def. 4.5.1)).

Figure 1: An example of “indirect confounding” from WC‘08. Z stands for a treatment taken in response to a test W, whose outcome depend ends on a previous treatment X. U is unobserved. [WC‘08 attribute this example to Robins and Wasserman (1997); an identical structure is treated in Causality, p. 119, Fig. 4.4, as well as in Pearl and Robins (1995).]
Solution:
P(y|do(x,z))
=P(y|x, do(z)) (since X is randomized)
= ∑w P(Y|x,w,do(z))P(w|x, do(z)) (by Rule 1 of do-calculus)
= ∑w P(Y|x,w,z)P(w|x) (by Rule 2 and Rule 3 of do-calculus)
We are done, because the last expression consists of estimable factors. What makes this problem appear difficult in the linear model treated by WC‘08 is that the direct effect of X on Y (say α) cannot be identified using a simple adjustment. As we can see from the graph, there is no set S that separates X from Y in Gα. This means that α cannot be estimated as a coefficient in a regression of Y on X and S. Readers of Causality, Chapter 5, would not panic by such revelation, knowing that there are dozens of ways to identify a parameter, going way beyond adjustment (surveyed in Chen and Pearl (2014)). WC‘08 identify α using one of these methods, and their solution coincides of course with the general derivation given above.
The example above demonstrates that the direct effect of X on Y (as well as Z on Y ) can be identified nonparametrically, which extends the linear analysis of WC‘08. It also demonstrates that the effect is identifiable even if we add a direct effect from X to Z, and even if there is an unobserved confounder between X and W – the derivation is almost the same (see Pearl (2009, p. 122)).
Most importantly, readers of Causality also know that, once we write the problem as “Find P(y|do(x, z))” it is essentially solved, because the completeness of the do-calculus together with the algorithmic results of Tian and Shpitser can deliver the answer in polynomial time, and, if terminated with failure, we are assured that the effect is not estimable by any method whatsoever.
3 Conclusions
It is hard to explain why tools of causal inference encounter slower acceptance than tools in any other scientific endeavor. Some say that the difference comes from the fact that humans are born with strong causal intuitions and, so, any formal tool is perceived as a threatening intrusion into one’s private thoughts. Still, the reluctance shown by Cox and Wermuth seems to be of a different kind. Here are a few examples:
Cox and Wermuth (CW’15) write:
“…some of our colleagues have derived a ‘causal calculus’ for the challenging
process of inferring causality; see Pearl (2015). In our view, it is unlikely that
a virtual intervention on a probability distribution, as specified in this calculus,
is an accurate representation of a proper intervention in a given real world
situation.” (p. 3)
These comments are puzzling because the do-operator and its associated “causal calculus” operate not “on a probability distribution,” but on a data generating model (i.e., the DAG). Likewise, the calculus is used, not for “inferring causality” (God forbid!!) but for predicting the effects of interventions from causal assumptions that are already encoded in the DAG.
In WC‘14 we find an even more puzzling description of “virtual intervention”:
“These recorded changes in virtual interventions, even though they are often
called ‘causal effects,’ may tell next to nothing about actual effects in real interventions
with, for instance, completely randomized allocation of patients to
treatments. In such studies, independence result by design and they lead to
missing arrows in well-fitting graphs; see for example Figure 9 below, in the last
subsection.” [our Fig. 1]
“Familiarity is the mother of acceptance,” say the sages (or should have said). I therefore invite my colleagues David Cox and Nanny Wermuth to familiarize themselves with the miracles of do-calculus. Take any causal problem for which you know the answer in advance, submit it for analysis through the do-calculus and marvel with us at the power of the calculus to deliver the correct result in just 3–4 lines of derivation. Alternatively, if we cannot agree on the correct answer, let us simulate it on a computer, using a well specified data-generating model, then marvel at the way do-calculus, given only the graph, is able to predict the effects of (simulated) interventions. I am confident that after such experience all hesitations will turn into endorsements.
BTW, I have offered this exercise repeatedly to colleagues from the potential outcome camp, and the response was uniform: “we do not work on toy problems, we work on real-life problems.” Perhaps this note would entice them to join us, mortals, and try a small problem once, just for sport.
Let’s hope,
Judea
References
Chen, B. and Pearl, J. (2014). Graphical tools for linear structural equation modeling. Tech. Rep. R-432,
Cox, D. and Wermuth, N. (2015). Design and interpretation of studies: Relevant concepts from the past and some extensions. Observational Studies This issue.
Pearl, J. (2009). Causality: Models, Reasoning, and Inference. 2nd ed. Cambridge Uni- versity Press, New York.
Pearl, J. (2015). Trygve Haavelmo and the emergence of causal calculus. Econometric Theory 31 152–179. Special issue on Haavelmo Centennial.
Pearl, J. and Robins, J. (1995). Probabilistic evaluation of sequential plans from causal models with hidden variables. In Uncertainty in Artificial Intelligence 11 (P. Besnard and S. Hanks, eds.). Morgan Kaufmann, San Francisco, 444–453.
Robins, J. M. and Wasserman, L. (1997). Estimation of effects of sequential treatments by reparameterizing directed acyclic graphs. In Proceedings of the Thirteenth Conference on Uncertainty in Artificial Intelligence (UAI ‘97). Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 409–420.
Wermuth, N. and Cox, D. (2008). Distortion of effects caused by indirect confounding. Biometrika 95 17–33.
Wermuth, N. and Cox, D. (2014). Graphical Markov models: Overview. ArXiv: 1407.7783.